kmeans与kmeans++的python实现,,一.kmeans聚类
kmeans与kmeans++的python实现,,一.kmeans聚类
一.kmeans聚类:
基本方法流程
1.首先随机初始化k个中心点
2.将每个实例分配到与其最近的中心点,开成k个类
3.更新中心点,计算每个类的平均中心点
4.直到中心点不再变化或变化不大或达到迭代次数
优缺点:该方法简单,执行速度较快。但其对于离群点处理不是很好,这是可以去除离群点。kmeans聚类的主要缺点是随机的k个初始中心点的选择不够严谨,因为是随机,所以会导致聚类结果准确度不稳定。
二.kmeans++聚类:
kmeans++方法是针对kmeans的主要缺点进行改进,通过在初始中心点的选择上改进不足。
中心点的选择:
1.首先随机选择一个中心点
2.计算每个点到与其最近的中心点的距离为dist,以正比于dist的概率,随机选择一个点作为中心点加入中心点集中,重复直到选定k个中心点
3.计算同kmeans方法
三.评估方法
误差平方和可以评估每次初始中心点选择聚类的优劣,公式如下:
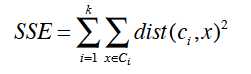
计算每个点到它自己的类的中心点的距离的平方和,外层是不同类间的和。根据每次初始点的选择聚类结果计算SSE,SSE值越小结果越好。
四.代码
1 #!/usr/bin/python 2 # -*- coding: utf-8 -*- 3 import math 4 import codecs 5 import random 6 7 #k-means和k-means++聚类,第一列是label标签,其它列是数值型数据 8 class KMeans: 9 10 #一列的中位数 11 def getColMedian(self,colList): 12 tmp = list(colList) 13 tmp.sort() 14 alen = len(tmp) 15 if alen % 2 == 1: 16 return tmp[alen // 2] 17 else: 18 return (tmp[alen // 2] + tmp[(alen // 2) - 1]) / 2 19 20 #对数值型数据进行归一化,使用绝对标准分[绝对标准差->asd=sum(x-u)/len(x),x的标准分->(x-u)/绝对标准差,u是中位数] 21 def colNormalize(self,colList): 22 median = self.getColMedian(colList) 23 asd = sum([abs(x - median) for x in colList]) / len(colList) 24 result = [(x - median) / asd for x in colList] 25 return result 26 27 ‘‘‘ 28 1.读数据 29 2.按列读取 30 3.归一化数值型数据 31 4.随机选择k个初始化中心点 32 5.对数据离中心点距离进行分配 33 ‘‘‘ 34 def __init__(self,filePath,k): 35 self.data={}#原始数据 36 self.k=k#聚类个数 37 self.iterationNumber=0#迭代次数 38 #用于跟踪在一次迭代改变的点 39 self.pointsChanged=0 40 #误差平方和 41 self.SSE=0 42 line_1=True 43 with codecs.open(filePath,‘r‘,‘utf-8‘) as f: 44 for line in f: 45 # 第一行为描述信息 46 if line_1: 47 line_1=False 48 header=line.split(‘,‘) 49 self.cols=len(header) 50 self.data=[[] for i in range(self.cols)] 51 else: 52 instances=line.split(‘,‘) 53 column_0=True 54 for ins in range(self.cols): 55 if column_0: 56 self.data[ins].append(instances[ins])# 0列数据 57 column_0=False 58 else: 59 self.data[ins].append(float(instances[ins]))# 数值列 60 self.dataSize=len(self.data[1])#多少实例 61 self.memberOf=[-1 for x in range(self.dataSize)] 62 63 #归一化数值列 64 for i in range(1,self.cols): 65 self.data[i]=self.colNormalize(self.data[i]) 66 67 #随机从数据中选择k个初始化中心点 68 random.seed() 69 #1.下面是kmeans随机选择k个中心点 70 #self.centroids=[[self.data[i][r] for i in range(1,self.cols)] 71 # for r in random.sample(range(self.dataSize),self.k)] 72 #2.下面是kmeans++选择K个中心点 73 self.selectInitialCenter() 74 75 self.assignPointsToCluster() 76 77 #离中心点距离分配点,返回这个点属于某个类别的类型 78 def assignPointToCluster(self,i): 79 min=10000 80 clusterNum=-1 81 for centroid in range(self.k): 82 dist=self.distance(i,centroid) 83 if dist<min: 84 min=dist 85 clusterNum=centroid 86 #跟踪改变的点 87 if clusterNum!=self.memberOf[i]: 88 self.pointsChanged+=1 89 #误差平方和 90 self.SSE+=min**2 91 return clusterNum 92 93 94 #将每个点分配到一个中心点,memberOf=[0,1,0,0,...],0和1是两个类别,每个实例属于的类别 95 def assignPointsToCluster(self): 96 self.pointsChanged=0 97 self.SSE=0 98 self.memberOf=[self.assignPointToCluster(i) for i in range(self.dataSize)] 99 100 # 欧氏距离,d(x,y)=math.sqrt(sum((x-y)*(x-y)))101 def distance(self,i,j):102 sumSquares=0103 for k in range(1,self.cols):104 sumSquares+=(self.data[k][i]-self.centroids[j][k-1])**2105 return math.sqrt(sumSquares)106 107 #利用类中的数据点更新中心点,利用每个类中的所有点的均值108 def updateCenter(self):109 members=[self.memberOf.count(i) for i in range(len(self.centroids))]#得到每个类别中的实例个数110 self.centroids=[111 [sum([self.data[k][i] for i in range(self.dataSize)112 if self.memberOf[i]==centroid])/members[centroid]113 for k in range(1,self.cols)]114 for centroid in range(len(self.centroids))]115 116 ‘‘‘迭代更新中心点(使用每个类中的点的平均坐标),117 然后重新分配所有点到新的中心点,直到类中成员改变的点小于1%(只有不到1%的点从一个类移到另一类中)118 ‘‘‘119 def cluster(self):120 done=False121 while not done:122 self.iterationNumber+=1#迭代次数123 self.updateCenter()124 self.assignPointsToCluster()125 #少于1%的改变点,结束126 if float(self.pointsChanged)/len(self.memberOf)<0.01:127 done=True128 print("误差平方和(SSE): %f" % self.SSE)129 130 #打印结果131 def printResults(self):132 for centroid in range(len(self.centroids)):133 print(‘\n\nCategory %i\n=========‘ % centroid)134 for name in [self.data[0][i] for i in range(self.dataSize)135 if self.memberOf[i]==centroid]:136 print(name)137 138 #kmeans++方法与kmeans方法的区别就是初始化中心点的不同139 def selectInitialCenter(self):140 centroids=[]141 total=0142 #首先随机选一个中心点143 firstCenter=random.choice(range(self.dataSize))144 centroids.append(firstCenter)145 #选择其它中心点,对于每个点找出离它最近的那个中心点的距离146 for i in range(0,self.k-1):147 weights=[self.distancePointToClosestCenter(x,centroids)148 for x in range(self.dataSize)]149 total=sum(weights)150 #归一化0到1之间151 weights=[x/total for x in weights]152 153 num=random.random()154 total=0155 x=-1156 while total<num:157 x+=1158 total+=weights[x]159 centroids.append(x)160 self.centroids=[[self.data[i][r] for i in range(1,self.cols)] for r in centroids]161 162 def distancePointToClosestCenter(self,x,center):163 result=self.eDistance(x,center[0])164 for centroid in center[1:]:165 distance=self.eDistance(x,centroid)166 if distance<result:167 result=distance168 return result169 170 #计算点i到中心点j的距离171 def eDistance(self,i,j):172 sumSquares=0173 for k in range(1,self.cols):174 sumSquares+=(self.data[k][i]-self.data[k][j])**2175 return math.sqrt(sumSquares)176 177 if __name__==‘__main__‘:178 kmeans=KMeans(‘filePath‘,3)179 kmeans.cluster()180 kmeans.printResults()kmeans与kmeans++的python实现
评论关闭