实现简单的垃圾邮件过滤器,来讲解机器学习的概念,垃圾邮件过滤器讲解,未经许可,禁止转载!英文
实现简单的垃圾邮件过滤器,来讲解机器学习的概念,垃圾邮件过滤器讲解,未经许可,禁止转载!英文
本文由 编橙之家 - Patrick_颜 翻译,XiaoxiaoLi 校稿。未经许可,禁止转载!英文出处:Benjamin Cohen。欢迎加入翻译组。
这个教程简单地介绍了如何使用 Python 2.x 和 Weka 进行机器学习。Weka 是一个数据处理和机器学习工具。这篇文章通过实现一个简单的垃圾邮件过滤器来讲解机器学习的概念。
这篇文章是由 Codementor 团队根据他们一个关注自然语言处理的数据科学家 Benjamin Cohen 的一个师生互动来创作的。
什么是机器学习?
简单来说,机器学习是一种基本数据的学习。回到以前我们没有大量的数据和强大的计算能力的时候,人们尝试手写规则来解决许多问题。例如,当你看到{{some word}},它很可能是垃圾邮件。当邮件里出现链接,它很可能是垃圾邮件。它们确实是可用的,但是由于问题变得越来越复杂,规则组合开始变得难以掌控,包括如何记录,传递以及处理它们。许多解决这样问题的技术都属于机器学习这个范畴内。从根本上说,你要解决如何自动地从数据的某些特征中学习他们之间的关系。
在机器学习中,我们尝试解决的一个重要问题叫做分类。简单地说,它决定了把东西放进什么类。例如,识别电子邮件是否是垃圾邮件,或者识别一张图片是狗还是猫。甚至还可以把数据分为两种或多种。
也就是说,我们真正需要开发的是一个能够自动区分两个或多个类别的系统。在这次练习中,我们要实现的是一个能识别垃圾邮件和正常邮件的系统。我们不打算手动编写规则来完成所有的这些功能。完成这个工作或者其他任何机器学习的问题的一件必要的事情就是收集数据集。机器学习的基本流程是从这些数据集中学习规则(可以代表这些数据集的规则),然后用学习到的规则来预测新的数据。换句话说,我们不需要一个数据集作为支持,告诉机器什么是正确的,或者我们的数据看起来像什么,也不用为机器去开发规则。我们需要的是收集让机器学习的材料。
值得注意的是,我们要完成的任务的数据集已经准备好了。但是一般来说,当你解决一个问题的时候,你通常还没有数据,并且你不知道你需要什么数据。
如果你是写一个系统来识别垃圾邮件,那么在这个练习中我们用的数据集正是你想要的,但事实上作为一个应用程序你可能需要找到其他的数据集来交叉验证。电子邮件的地址是一个不稳定的的特征,它们会经常被关闭以至于发送人会创建许多新的邮件地址。你可以做的一件事是判断某个域名发送垃圾邮件的概率。例如,不会有许多人用 gmail 来发送垃圾邮件,因为谷歌对于检测和关闭垃圾邮件账户做的是非常棒的。然而,一些像 hotmail 这样的域名可能有一个特征:如果发送者使用了 hotmail,它很可能就是垃圾邮件,因此你完全可以从检测邮件地址中学习到特征。其他的一些我们能看到的典型特征是元信息,例如邮件是什么时间发送的。在这个练习中所有这些我们可以看到的数据事实上是来自邮件,即文本内容。
练习
这个是 Github 项目的链接,你可以创建分支并继续开发这个项目。首先确定你已经在你的机器上安装了 Weka ——一款免费的软件。
我们将要用的数据集大概包含了1300个电子邮件。你可以快速地浏览这两个文件夹看看都有什么邮件,它们分别是垃圾邮件和非垃圾邮件。例如:
Find Peace, Harmony, Tranquility, And Happiness Right Now!<html><head></head><body bgcolor=3Dblack> <table border=3D0 cellspacing=3D0 cellpadding=3D5 align=3Dcenter><tr><th b= gcolor=3D"#8FB3C5"> <table border=3D0 cellspacing=3D0 cellpadding=3D5 align=3Dcenter><tr><th b= gcolor=3D"#000000"> <table border=3D0 cellspacing=3D0 cellpadding=3D0 align=3Dcenter> <tr> <th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D= pw"> <img src=3D"http://giftedpsychic.com/images/r1c1.jpg" width=3D279 height=3D= 286 border=3D0></a></th> <th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D= pw"> <img src=3D"http://giftedpsychic.com/images/r1c2.gif" width=3D301 height=3D= 286 border=3D0></a></th> </tr> <tr> <th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D= pw"> <img src=3D"http://giftedpsychic.com/images/r2c1.jpg" width=3D279 height=3D= 94 border=3D0></a></th> <th><a href=3D"http://psychicrevenue.com/cgi-bin/refer.cgi?pws01014&site=3D= pw"> <img src=3D"http://giftedpsychic.com/images/r2c2.jpg" width=3D301 height=3D= 94 border=3D0></a></th> </tr> </table></th></tr></table</th></tr></table></body></html>
这个是相当典型的垃圾邮件,然后下面这个
Re: EntrepreneursManoj Kasichainula wrote; >http://www.snopes.com/quotes/bush.htm > >Claim: President George W. Bush proclaimed, "The problem with >the French is that they don't have a word for entrepreneur." > >Status: False. >Lloyd Grove of The Washington Post was unable to reach Baroness >Williams to gain her confirmation of the tale, but he did >receive a call from Alastair Campbell, Blair's director of >communications and strategy. "I can tell you that the prime >minister never heard George Bush say that, and he certainly >never told Shirley Williams that President Bush did say it," >Campbell told The Post. "If she put this in a speech, it must >have been a joke." So some guy failed to reach the source, but instead got spin doctor to deny it. Wot, is he thick enough to expect official confirmation that, yes, Blair is going around casting aspersions on Bush??? It's an amusing anecdote, I don't know if it's true or not, but certainly nothing here supports the authoritative sounding conclusion "Status: False". R http://xent.com/mailman/listinfo/fork
是一个正常的邮件。
总而言之,快速的浏览了这两个文件夹以后,你会发现它们是相当有代表性的邮件,能看出来它是垃圾邮件或者不是。这确实很重要,因为如果我们的数据不具有代表性,机器学习到的东西将没有任何意义。
总结一下要点,我们要尝试判断一个特征,看它是否能让我们区分数据集中的非垃圾邮件和垃圾邮件。希望将来它可以帮助我们检测出垃圾邮件。
何时用到自然语言处理?
如果你已经注意到,来自”垃圾邮件“与“非垃圾邮件”中内容都是文字。我们作为人类可以很好的理解文字和语言,但是计算机能理解的却非常的少。在这个练习中,我们得把英语转换成计算机可以理解的语言。一般来说,可以转换成数字。这就是自然语言处理的由来,我们试着让计算机理解这些信息的上下文要点。在机器学习的部分就是理解这些数字形成模型并且在将来应用这个模型。
什么是特征?
在我们这个案例中,特征主要是我们输入信息的一种数字化的转变,或者说仅仅是一个机器可以学习的数字。我们打算获取一组数字,或者被叫做特征。它可以像这样代表一封邮件:
The DEBT-$AVER Program SKYXTGM<HTML><HEAD> <META http-equiv=3DContent-Type content=3D"text/html; charset=3Diso-8859-1= "> </HEAD><BODY><CENTER> <A href=3D"http://marketing-fashion.com/user0205/index.asp?Afft=3DDP15"> <IMG src=3D"http://61.129.68.17/debt1.gif" border=3D0></A> <BR><BR><FONT face=3DArial,Helvetica color=3D#000000 size=3D1> Copyright 2002 - All rights reserved<BR><BR>If you would no longer like us= to contact you or feel that you have<BR>received this email in error, please <A href=3D"http://marketing-fashion.com/light/watch.asp">click here= to unsubscribe</A>.</FONT></CENTER></BODY></HTML>
我们的数字特征挑选得越好,模型就能更有希望地识别我们的电子邮件。
在挑选任何其他特征之前,我们直接来看字数。features.py是完成这个功能的代码:
def numwords(emailtext):
splittext = emailtext.split(" ")
return len(splittext)
但是,为了让Weka分析这个数据,我们需要把它转换为.arff文件。
feature_extract.py是一个脚本. 现在你不用担心这是什么,但是如果你感兴趣话这里有代码:
import os, re
import math, glob
import features
import inspect
def main():
arff = open("spam.arff", "w")
ben_functions = inspect.getmembers(features, inspect.isfunction)
feature_funcitons = []
feature_funcitons += list([f[1] for f in ben_functions])
RELATION_NAME = "spam"
arff.write("@RELATION " + RELATION_NAME + "n")
for feature in feature_funcitons:
arff.write("@ATTRIBUTE " +
str(feature.__name__) + " REALn") #change this if we
#have non-real number
#values
###PREDEFINED USER FEATURES#######
arff.write("@ATTRIBUTE SPAM {True, False}n")
arff.write("@DATAn")
spam_directory = "is-spam"
not_spam = "not-spam"
os.chdir(spam_directory)
for email in glob.glob("*"):#ITERATE THROUGH ALL DATA HERE
extract_features(open(email).read(), feature_funcitons, arff, True)
os.chdir('../'+not_spam)
for email in glob.glob("*"):#ITERATE THROUGH ALL DATA HERE
extract_features(open(email).read(), feature_funcitons, arff, False)
def numwords(emailtext):
splittext = emailtext.split(" ")
return len(splittext)
def extract_features(data, feature_funcitons, arff, spam):
values = []
buff = ""
for feature in feature_funcitons:
value = feature(data)
values.append(value)
if spam:
buff += (",".join([str(x) for x in values]) + ', True' + "n")
else:
buff += (",".join([str(x) for x in values]) + ', False' + "n")
arff.write(buff)
if __name__ == "__main__":
main()
这个脚本基本上适用于我们在features.py中写的所有特征并且把这些特征放到.arff文件中
那么,运行feature_extract.py之后,我们来看一下spam.arff文件:
@RELATION spam
@ATTRIBUTE numwords REAL
@ATTRIBUTE SPAM {True, False}
@DATA
1003,True
638, True
74, True
88, True
@Relation表示问题的名字,然后每个@ATTRIBUTE是一个特征。我们这里第一个特征是字数,REAL表示它是一个实数。最后一个属性表示不同的分类,并且在我们这个例子中,SPAM可以是True或者False。运行之后,我们的数据包含了每一个属性的值。例如,开头是1003的那一行表示该邮件有1003个单词,True表示它是垃圾邮件。
这个.arff 文件并没有什么内容需要必须看,我们只是把它扔进Weka中。
运行Weka并读取spam.arff文件
在预处理选项中,左边那一列包含了所有的特征。如果你点击“SPAM”,在右面一列,是否是垃圾邮件的分布图会显示出来。在这1388个邮件中,501个是垃圾邮件,887个不是。
让我们用Weka看一下numwords属性:
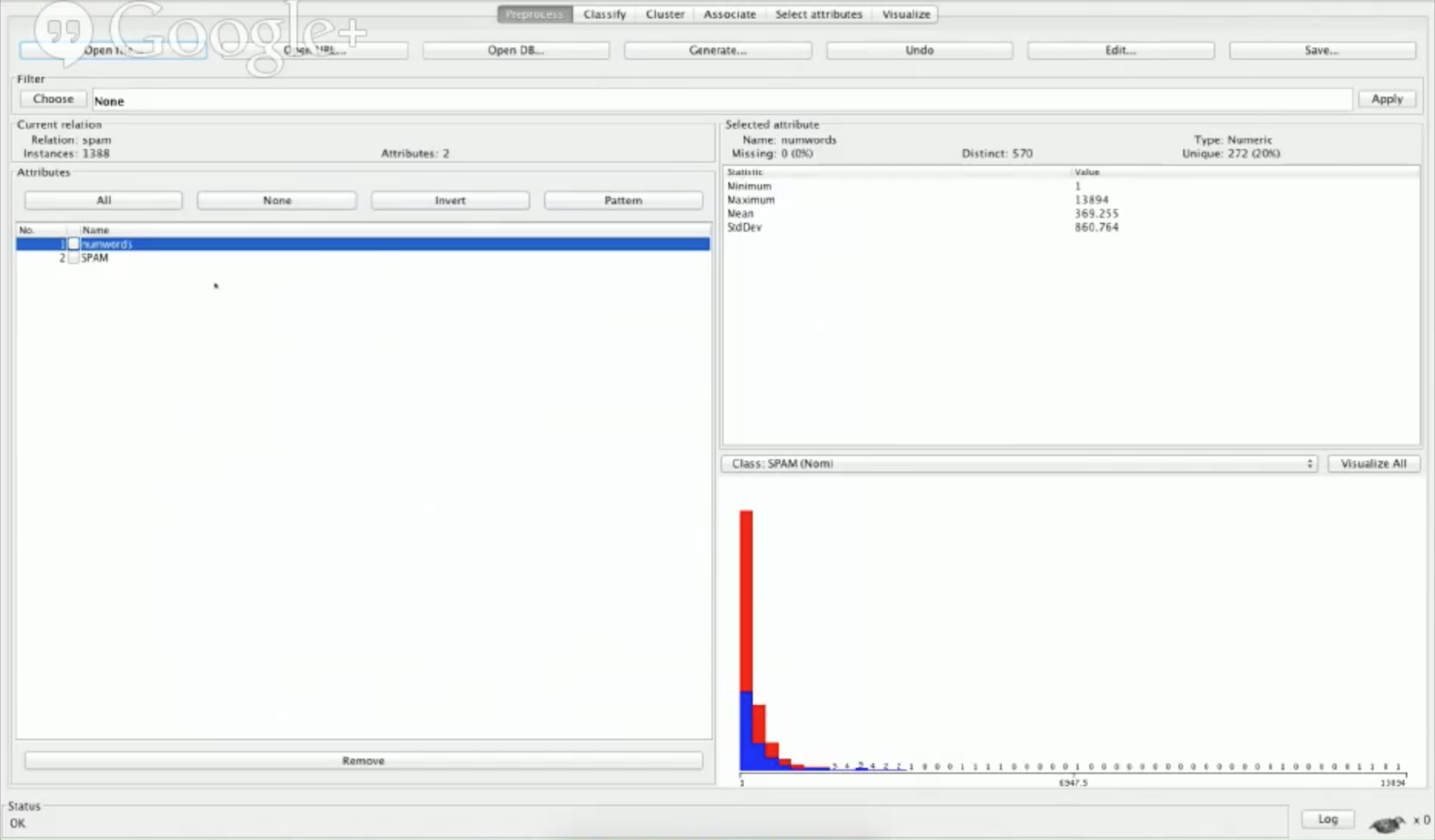
你会看到一个分布图,但是现在它并没有告诉我们很多。我们也会看到一些统计数字。例如,最少的字数是1,最大是13894,这是非常高的。由于我们有更多的特征,我们可以看到他们在分布中更多的不同之处,以及告诉我们哪一个是好的。
如何选择,创造,以及使用特征
下一件要做的事是查看Classify选项。
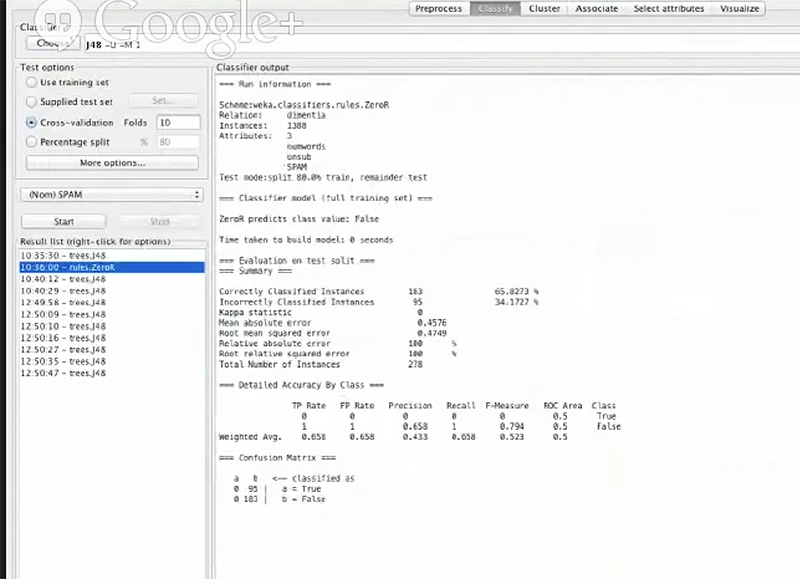
在这个选项中有许多信息,但是在这次任务中我们暂时忽略大多数功能。一个我们将会用到的重要功能是 classifiers box,这里面的 classifier 是我们如何学习模型的关键。根据你的问题,特定的分类器对特定的问题会非常的好用。如果你点击了 classifier box,你会看到在目录中有很多可展开的文件。
然后,我们可以选择测试选项。我们不仅仅需要训练模型,也需要一些方法来检验通过我们的特征学习的或观察的模型是否好用。我们可以学习一个模型,但是如果它被证明是完全没有用的,不会对我们有什么帮助。
在测试选项中,我们选择用 Percentage split。
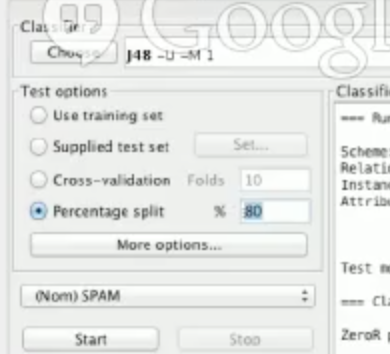
在 percentage split 后面填写 80% 后,它会用 80% 的数据训练一个模型。在我们这个项目中,1300 封电子邮件中大概有 1000 封左右用来训练。剩下的 20% 将被用来测试,然后我们会看看有多少比例的数据是正确的。
我们使用 percentage split 是因为我们不想遇到一个叫做“过拟合”的问题:从我们的数据中学习到的模型可能在现实世界中不存在。如果我们学习一个非常具体的数据集,而它们只是偶然的出现在我们的训练数据中,这个模型不会帮我们预测任何事,因为他不会在其他数据中被观察到。我们要牢记的是使用我们从未见过的数据来测试是非常重要的,因此我们可以模拟现实世界中的数据来测试我们的模型,而不是用训练过的数据继续测试。
我们最后会看一个过拟合的例子。现在首先选择一个叫做OneR的算法测试一下字数特征的表现如何。
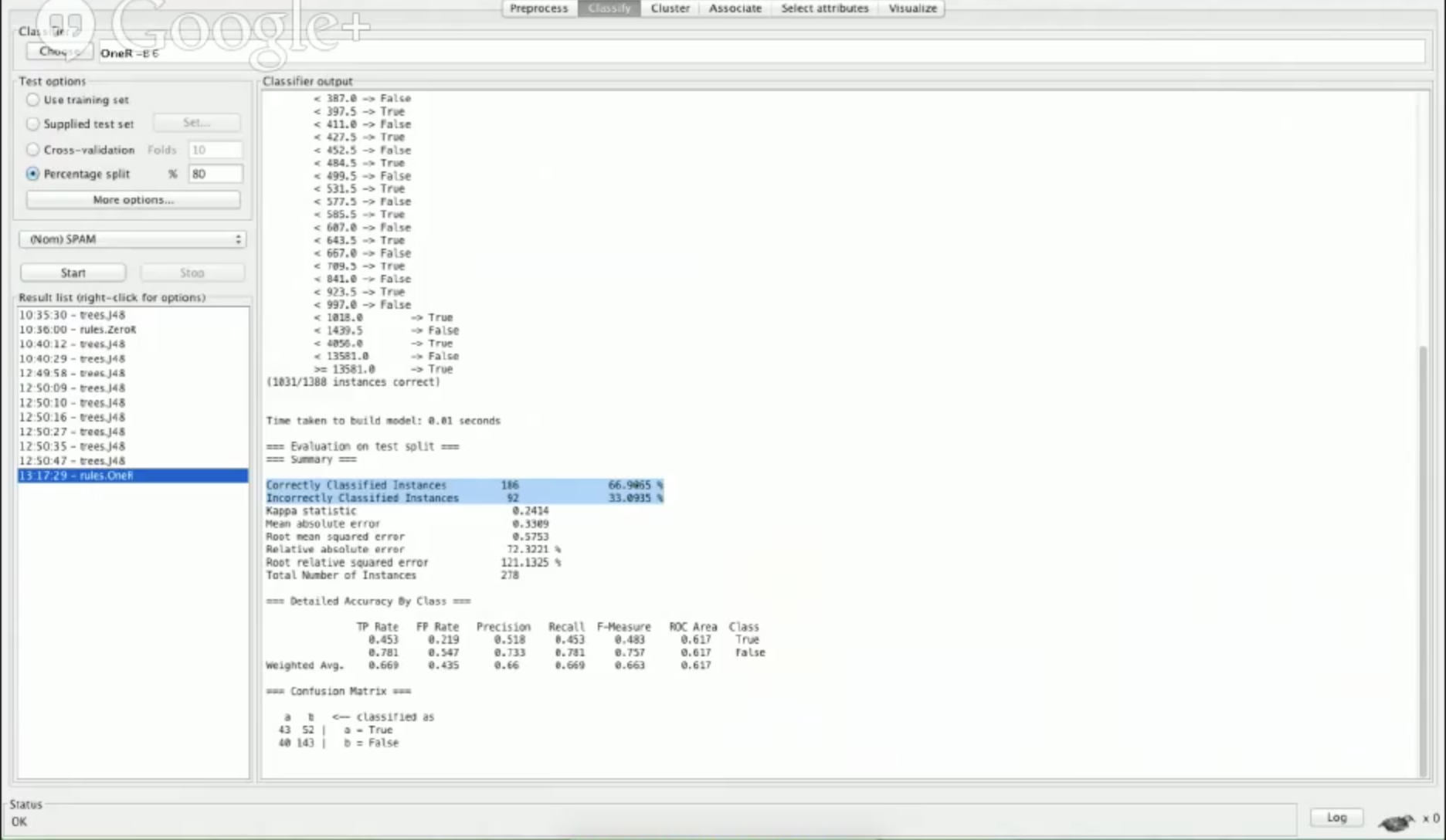
我们要重视的一个数字是“correctly classified instances”:
Correctly Classified Instances 186 66.9065 % Incorrectly Classified Instances 92 33.0935 %
这些数字代表我们的垃圾邮件检测率。可以看到,使用这些特征我们把 66.9% 的电子邮件正确的分类为垃圾邮件或者非垃圾邮件。第一次的检验结果看起来有不错的效果。
然而,66.8% 的准确率并不是很好,因为如果我们查看初始的数据分布会看到,我们有 1388 封邮件,887 封不是垃圾邮件,或者说 64% 不是垃圾邮件,因此 67% 的检测率并不高。
这个概念叫做基准线,它是个非常简单的分类,我们用来跟其他的结果进行比较。如果我们数据的分布是 50:50,并且我们得到 66.9% 的正确率的话,那么这是一个非常棒的结果因为我们提升了大概 17% 。但是我们仅仅提升了 3% 。
什么是混淆矩阵
在weka下面的部分,我们需要查看的数据是混淆矩阵:
=== Confusion Matrix === a b <— classified as 43 52 | a = True 40 147 | b = False
“a b” 那一行代表预测的类别,而“a,b”列代表实际的分类。这里 a 代表 spam = True,而 b 代表 spam = False
因此,在我们这个案例中,我们正确的分类43个实例,而分错了52个。最下面那一行展示了我们混淆的部分,或者说是我们做错的部分。
这个混淆矩阵很有帮助,因为如果左下角是 0 的话就表明我们把所有的数据分到了是垃圾邮件一类,但是它也意味着分类过于极端,我们应该通过微调参数来使我们的规则放松一点。
提升Weka的分类准确率
为了提高准确率,让我们回到 features.py 文件,然后写一些代码获得更多的特征。
我们当前的特征是获取邮件的所有文本内容并且返回字数。然后,它会通过 features_extract.py 自动的写入到 spam.arff 文件中。现在我们要加入一个特征来检测该邮件的内容包含在 HTML 中还是仅仅是纯文本内容。
我选择加入这个特征是因为我知道这会产生一个有趣的分布。一般来说,你可以通过观察数据集而快速地想出好的特征。由于你已经浏览了一些在非垃圾邮件文件夹中的文件,因此可以看到只有很少的正常邮件出现了 HTML 的格式。在垃圾邮件文件夹中,一些邮件似乎也在 HTML 格式,因此它可能是一个好的特征。
由于这次的任务只花费了不到 1 小时的时间,我们写出的是大概的方法来检测email是否在 HTML 中,它并不完美。
def has_html(emailtext): return 1 if "html" in emailtext.lower() else 0
我们认为如果邮件中出现了单词 HTML 则该邮件就有这个特征,可能并非如此,但这是最简单的方法。
在命令行运行 features_extract.py 脚本文件以后
python feature_extract.py
用 Weka 重新读取 .arff 文件然后会看到加入了 has_html 的特征:
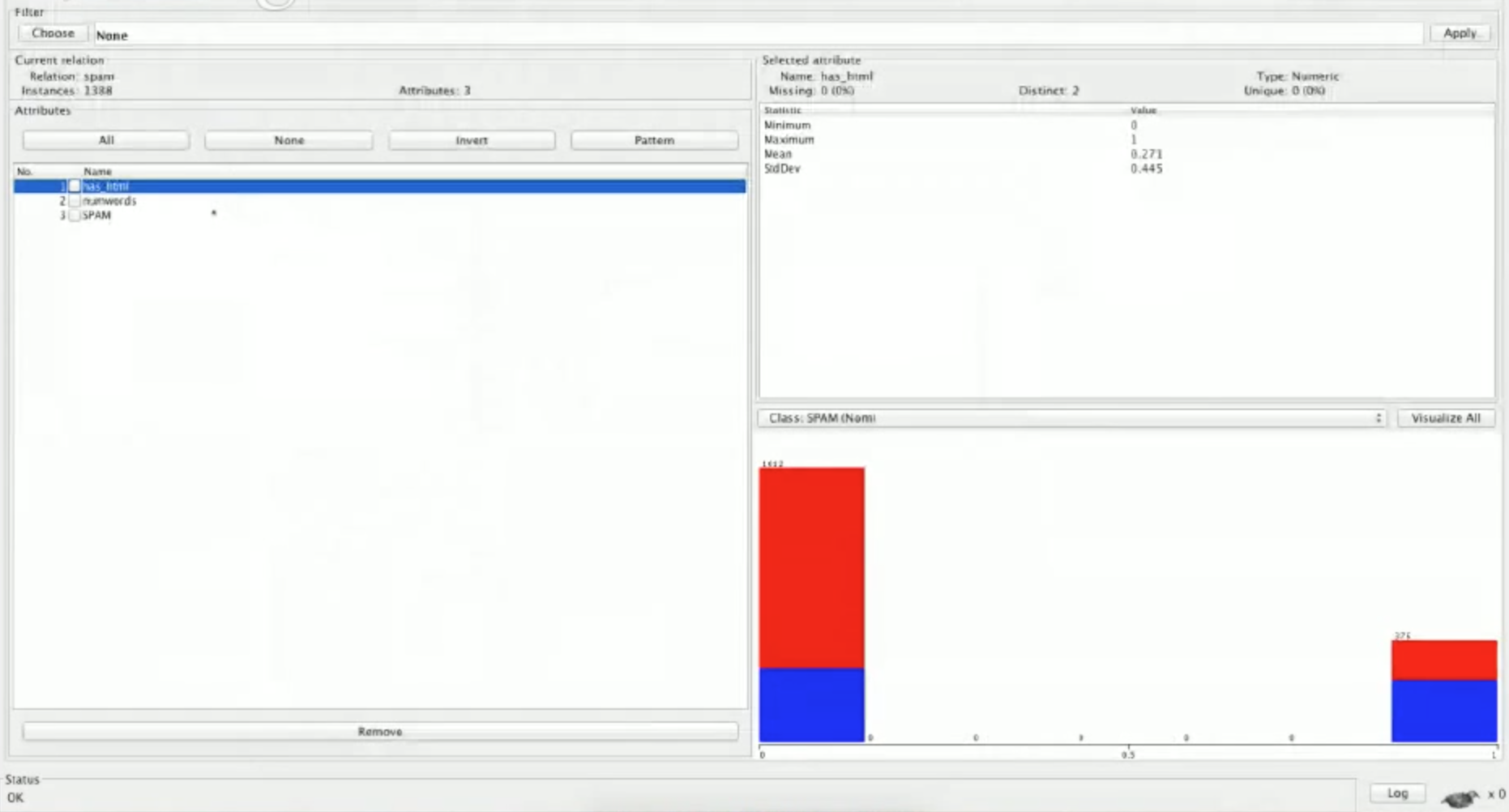
在这里平均值和标准差不会讲的太多。看一下我们的 SPAM 特征的图表,红色代表的是非垃圾邮件。因此我们可以看到在 has_html 这个特征中,多数的非垃圾邮件不包含 HTML ,并且多数的垃圾邮件含有 HTML 。这正是我们期待的,至少目测来看,我们是可以从这个特征中学习到东西的,因此这是一个很好的特征。
让我们继续在 features.py 写出第三个特征。基于我们的数据集,我已经观察到垃圾邮件有更多的链接由于它们想让你买东西,因此我想取他的链接数作为特征。
def num_links(emailtext):
return emailtext.count('http')
再次说明这个特征只是个近似值,我们不会去算精确的链接数由于这是更花费时间的。这个特征是假设任何时候只要电子邮件包含了 http 关键字,都会有相应的链接。
After running our features_extract.py again, we can re-open our spam.arff file on Weka:
再次运行 features_extract.py 文件之后,可以在 Weka 中重新打开 spam.arff 文件:
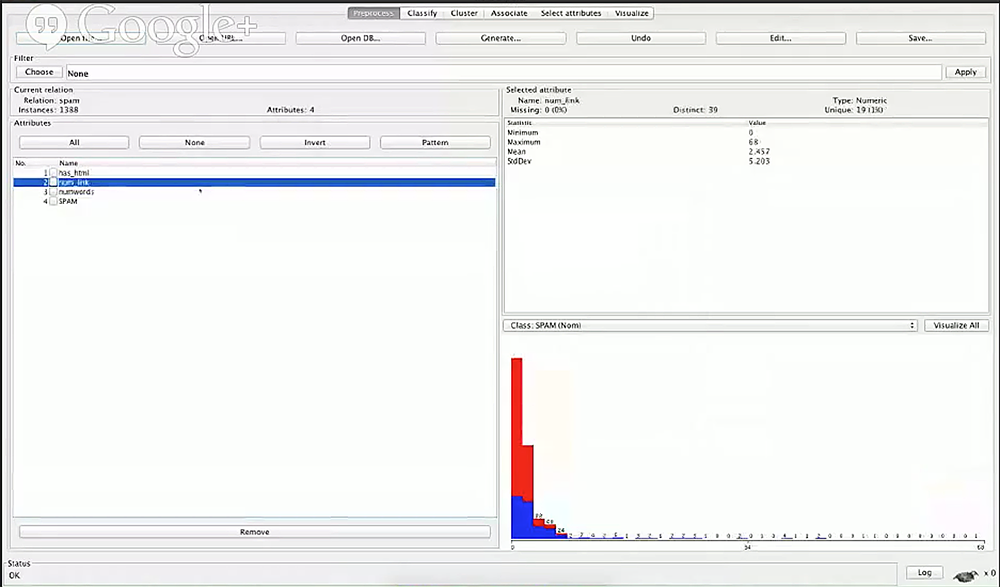
正如我们期待的那样,他们最小值是 0,因为有的电子邮件不包含链接;而其中一个的最大值是 68 。
有趣的是,如果你看了我们的分布图,你会发现在某些点(10 左右),所有超过 10 个链接的邮件都是垃圾邮件。因此这看起来确实是好的特征。现在我们可以制定一个规则:如果链接数大于 10,那么它肯定是垃圾邮件。还有一个基本的规则:如果一个邮件有更多的链接数,那么它更可能是垃圾邮件。
我们在Weka中测试一下新的特征,看看重新测试后准确率是否有提升。
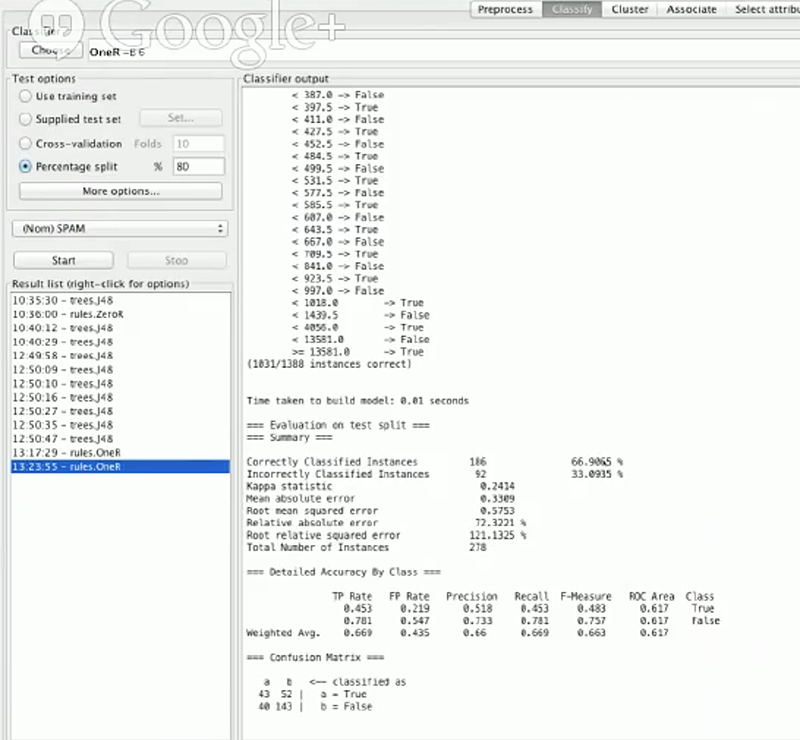
它看起来并没有什么改变,尽管我们用了更好的规则。原因可能是我们用了错误的分类器。OneR分类器是仅仅使用一个特征,并且基于那个特征来开发规则,因此即使我们重新测试它,它也仅仅看到numwords特征,并且基于它开发所有的规则。然而,现在我们有3个特征,并且不确定基于字数特征的分类是好用的。我们了解了has_html以及has_link是好用的并且想把他们合并到一起。下面切换到J48决策树分类器。
什么是决策树?
决策是是一个简单的概念,它与我们人类行为很相似。由于它本质上是由做决定开始,然后跟随一个路径。这里我找了一个经典的例子 http://jmvidal.cse.sc.edu/talks/decisiontrees/allslides.html :
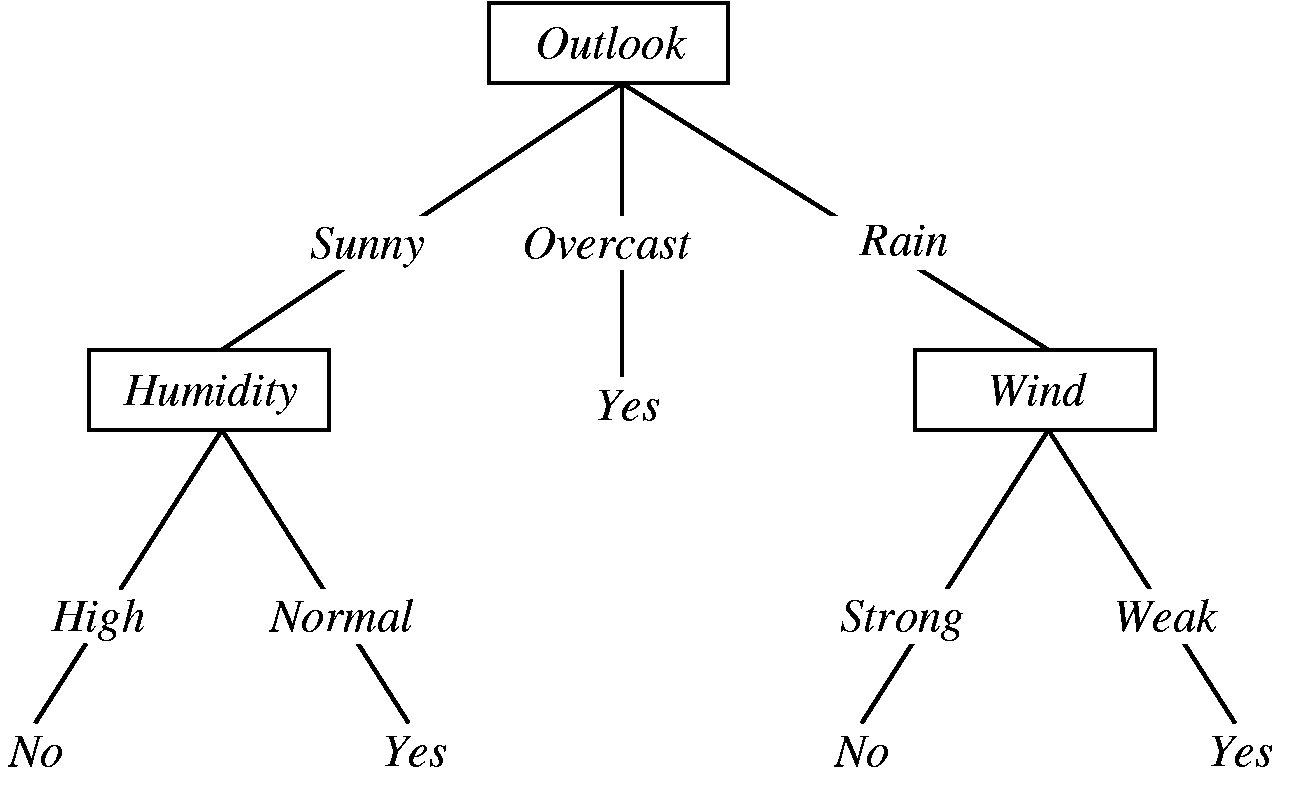
假如我们想去打网球。我们会看天气是晴天,阴天,还是雨天。如果是阴天,我们就去。如果是雨天,我们会看是否刮风。如果风太大,我们就不会去。如果风很小,我们就去。如果是晴天,我们会看湿度。如果湿度是正常的我们就去玩,如果太高则不会去。
你会看到我们基于一个变量做单独的决定,然后继续沿着那颗树做决定直到得出我们希望是正确的结论。建立这样的决策树有许多算法,但是这里我们不会讨论他们。
不管怎样,我们选择了 J48 分类器。我们看到:
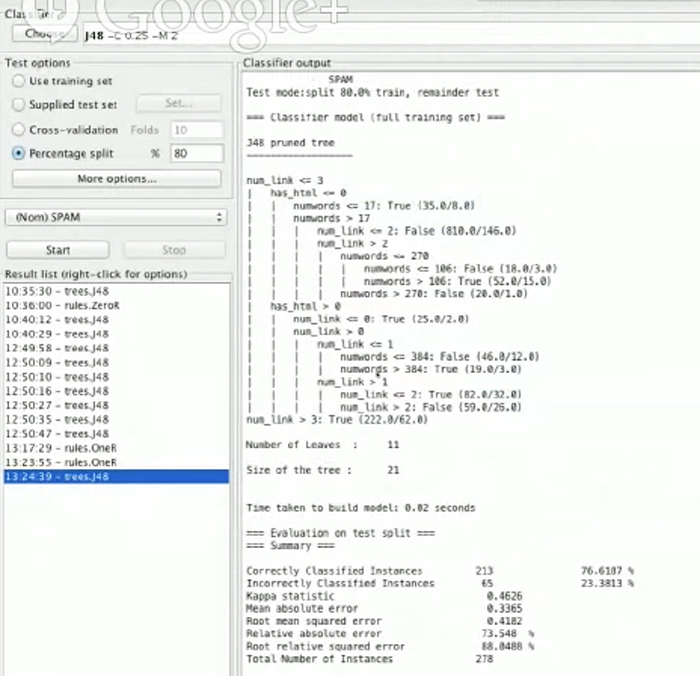
我们可以清楚的看到如何基于一颗树来做决定的,如果 num_link 大于 3 则为 True 。如果小于 3,我们会看它是否包含 html,同时它会把树分成两个树枝。然后我们继续根据其他的特征例如 num_link 和 numwords 向下做决策。
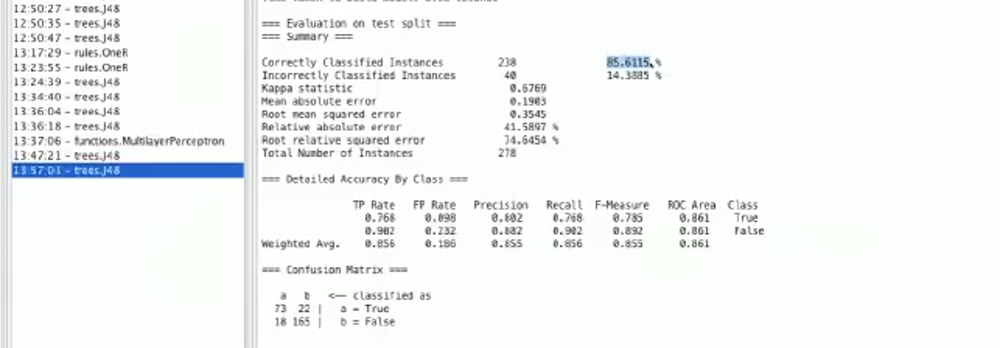
正如上面截图中你看到的那样,分类正确率已经提高到76.6%。
如何判断哪个规则比较重要
我将会给出一个简化的答案,由于完整的答案太过于复杂。从根本上说,有一个概念叫做”信息“,或者叫知识。我们可以这样问自己:”通过这个特征我们可以获得多少信息呢?“。
例如,如果有两个特征:晴天和多云天。我们在 4 个晴天和 4 个多云天打网球,并且在两个晴天和多云天不大网球。这样的信息没有跟我们任何帮助——我们通过观察天气没有获得任何信息,因为它是双向选择的;
如果我们观察多风天,每一次多风天我们不打网球,以及如果是多风天我们总是去打网球,那么我们通过检测多风的特征就获得了许多信息。因此,相对于晴天,观察每天是否多风会更有收益,这是因为我们通过观察晴天特征没有获取任何信息。
观察我们的模型你会注意到,我们首先会检查链接个数,那就意味着链接个数是一个获取很多信息的特征。事实上我们可以通过 Weka 来观察原始数据的信息获取情况。
让我们选择进入属性选择选项,选择 InfoGainAttributeEval 然后点击开始。会出现这个画面:
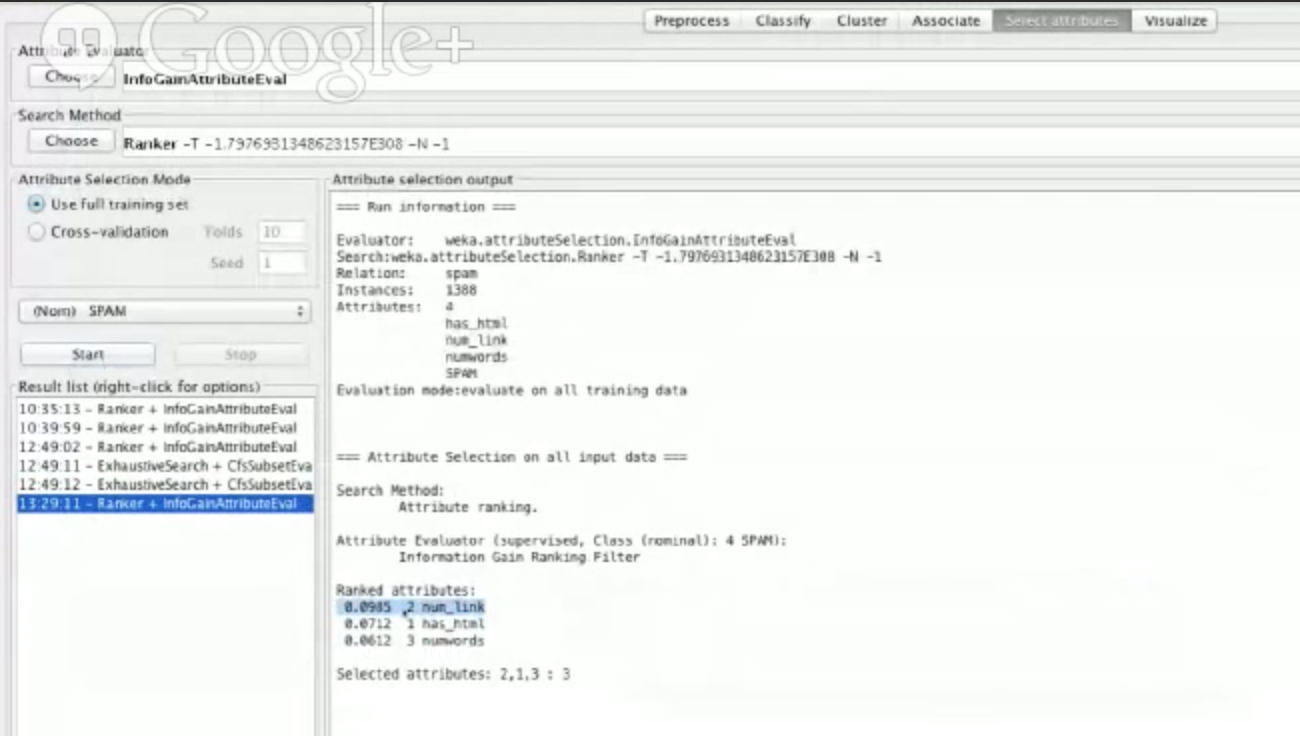
我们不需要关心所有数字的意义,但是我们可以看到 num_link 这个特征获取了大部分的信息,紧跟着是 has_html 和 numwords 。换句话说, num_link 是最好的特征。
为了进一步的阐述,我们可以在 features.py 中加一个虚拟特征:
def dummy(emailtext):
这个特征不管是什么电子邮件都会返回1。如果我们运行feature_extract.py然后在weka中重新读取spam.arff,我们应该看到虚拟特征没有任何信息获取。
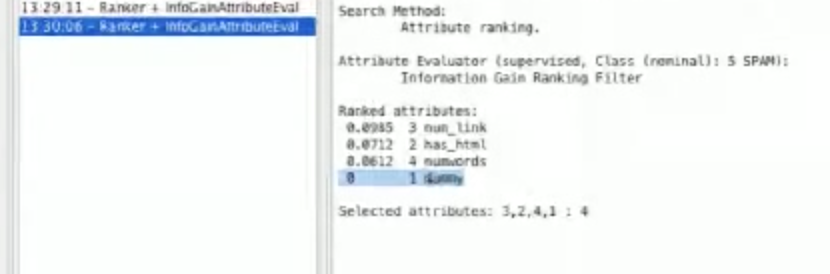
这是因为每个实例都有相同的值。
总结一下,我们本质上需要的特征是可以获取最多信息的特征。
过拟合
现在我们想要更多的特征帮我们来识别邮件。同样,这里有很多种方法把邮件中所有的文本从我们可以理解的状态转换成计算机可以理解的状态,它是一个单个数字或者是二元特征。
一位 Codementor 的用户建议使用一些具体的代表垃圾邮件的单词,例如”free“,”buy“,”join“,”start“, ”click“,”discount“。让我们在 features.py 文件中加入这些特征。通过空格分开所有的单词然后获得他们。
def spammy_words(emailtext):
spam_words = ['join', 'free', 'buy', 'start', 'click', 'discount']
splittext = emailtext.split(" ")
total = 0
for word in spam_words:
total += splittext.count(word) #appends the count of each of these words to total
return total
让我们给这个特征一个截图并在 Weka 中重新读取 spam.arff 。
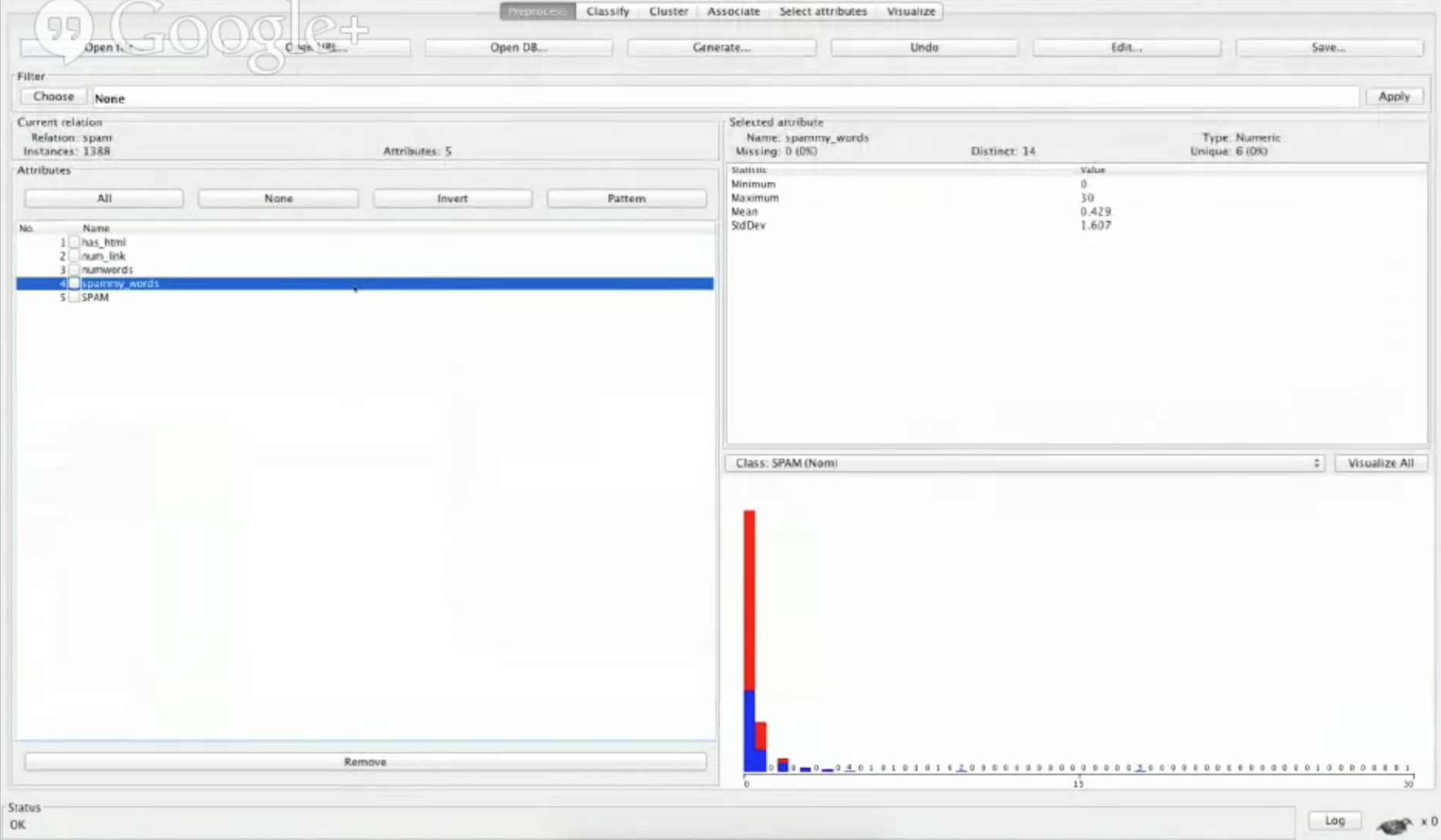
我们可以看到在这个分布中大多数的非垃圾邮件不包含任何垃圾邮件词汇,并且由于计数增长,柱状条会变得越蓝,这意味着如果邮件中包含越多垃圾邮件词汇就越有可能是垃圾邮件。
我们也来看一下信息获取:
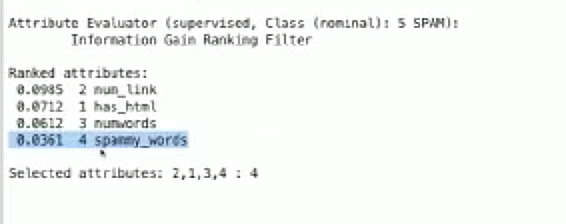
我们可以看到这里有一些信息获取,但是并不全。
至于我们的分类器,实际上我们可以看到准确率有轻微的下降。

并不是说 spammy_words 是个不好的特征,在我看来它是相当好的。让我们思考一下有什么可能愿意会导致分类准确率下降。
我个人看来,准确率下降是因为过拟合。如果你查看 Weka 中的那棵树,你会发现我们生成了许多规则-我估计至少有50个规则,并且他们的大多数都非常的具体。
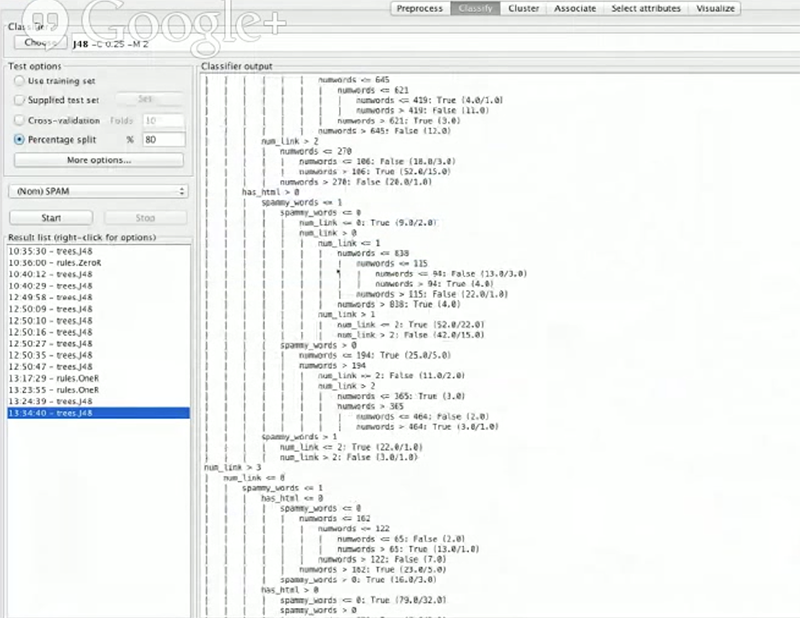
我们可能分析数据太过于具体,并且制定的规则也太具体,尤其是 spammy_words 特征,它并没有对信息获取很多贡献。但是我们可以用分类器做实验并且调整参数看看是否可以增加分类器准确率,让我尝试修复一下我们的 spammy_words 特征。
在之前,我们认为一些单词会表明为它是垃圾邮件。然而,根据我们的实验来看,作为人类我们是有偏见的,我们想到的单词可能不会出现在我们的数据集中。或者,它可能意味着单词‘free’仅仅是一个在邮件里普通常见的单词。
我们打算想个办法过滤垃圾单词:它会自动的生成一个列表而不是我们自己去想。
我们先来看一下单词的分布。我们应该设置垃圾邮件词汇和非垃圾邮件词汇的词典,然后像下面那样填进去:
import os, glob
spamwords = {}
notspamwords = {}
spam_directory = "is-spam"
not_spam = "not-spam"
os.chdir(spam_directory)
for email in glob.glob("*"):#ITERATE THROUGH ALL DATA HERE
text = open(email).read().lower().split(‘ ') #gets all the text of our emails and normalizes them to lower case
for word in text:
if word in spamwords:
spamwords[word] += 1
else:
spamwords[word] = 1
print spamwords
让我们保存上面的代码到文件 wordcounts.py 中然后运行它。我们会看到所有的单词构成了一个超级大的字典并且描述了单词出现的频率。他也得到了链接和 html 标签,但是我们要忽略他,并且可以通过改变 print spamwords 代码打印出这些词。
keys = sorted(spamwords.keys(), key=lambda x: spamwords[x], reversed=True`) for word in keys: print word, spamwords[word]
这里我们根据他们出现的频率排序。
然后我们会看到排在前面的词汇都是常见的(例如 for, a, and, you, of, to, the)。一开始我们会认为这些词汇不是很好,因为他们帮不上忙。我们不能找“a”这样的单词因为它会同时出现在垃圾邮件和非垃圾邮件中。
因此,想要真正解决统计经常出现在垃圾邮件中,而不会出现在非垃圾邮件中的词汇,我们只用改动一点代码,来统计出现在非垃圾邮件中的常用词汇:os.chdir(spam_directory) 改为 os.chdir(‘../’+not_spam)。
我们会注意到很奇怪的现象,Helvetica 是一个垃圾邮件中的常用词汇而在非垃圾邮件中并不存在。New, money, e-mail, receive, and business 也出现在垃圾邮件中但是在非垃圾邮件中出现的却如此之少,因此让我们对 spammy_words 特征做出改变。
def spammy_words(emailtext):
spam_words = ['helvetica', 'new', 'money', 'e-mail', 'receive', 'business']
splittext = emailtext.split(" ")
total = 0
for word in spam_words:
total += splittext.count(word) #appends the count of each of these words to total
return total
让我们也为非垃圾邮件词汇创造一个特征,可能也很有帮助。有趣的是许多电子邮件拼写是不同的。
def not_spammy_words(emailtext):
spam_words = ['email', 'people', 'time', 'please']
splittext = emailtext.split(" ")
total = 0
for word in spam_words:
total += splittext.count(word) #appends the count of each of these words to total
return total
加入这两个特征以后,现在在 Weka 中显示的准确率已经接近 79% 了。事实上我们可以看到许多有趣的事情仅仅通过检查实际的单词。我们用这些单词甚至单词的组合二元文法(一对单词)来训练我们的机器或者三元文法(三个单词一起)。例如,“free”可能在垃圾邮件与非垃圾邮件中都出现过,但是“free money”仅在垃圾邮件中出现。我们可以制定一个特征如果出现了“free money”则为垃圾邮件,而只出现“free”和“money”则不是。
其他的特征
通过观察我们的数据集或者实验你可能会注意到一件事情,垃圾邮件更倾向于在邮件中“表露身份”以及全部使用大写,然而正常人很少这样做。让我们根据这个观察再尝试加入两个特征。第一个是邮件文本是否全部是大写,另一个是大写字母所占比率即所有的大写字母个数除以小写字母个数。
def all_caps(emailtext): return 1 if emailtext == emailtext.upper() else 0 def cap_ratio(emailtext): lowers = float(len([f for f in emailtext if f == f.lower()])) uppers = float(len([f for f in emailtext if f == f.upper()])) return uppers/lowers
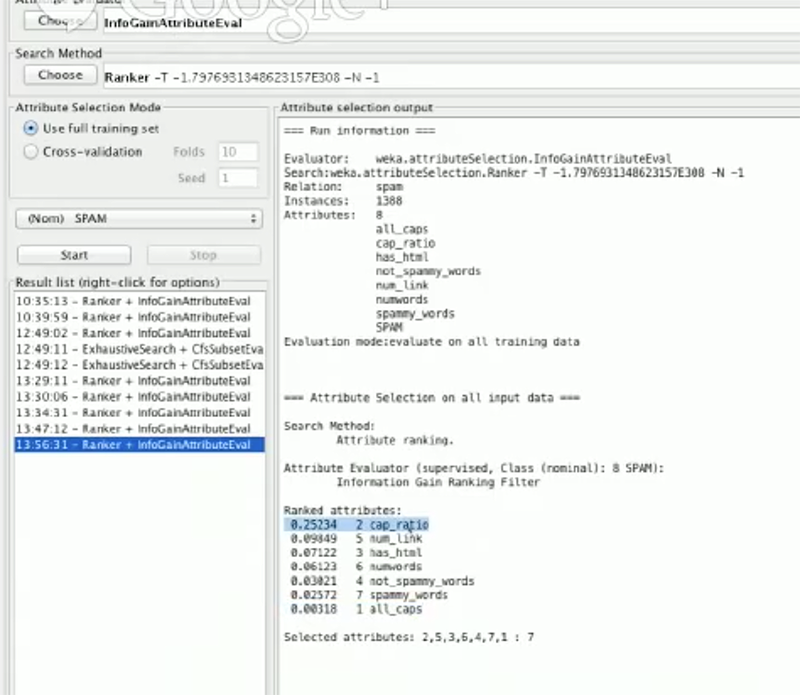
观察 Weka 中的结果,我们发现 all_caps 特征并没有给我们很多信息,但是 cap_ratio 特征告诉我们许多信息,并且它的分布图表明超过平均值的比率特征几乎都是垃圾邮件。
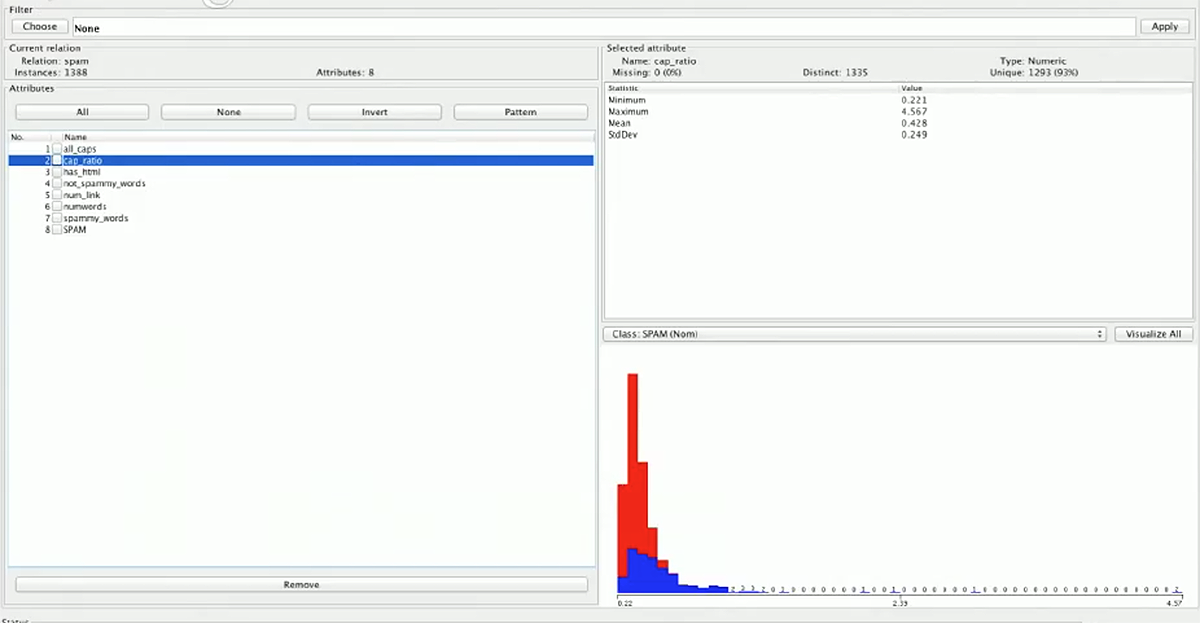
加入cap_ratio特征后使我们的准确率几乎达到了86%。
结束语
随着我们加了更多的特征,我们的模型训练起来变得更慢了,因为它会花费更多的时间来学习模型。现在我们已经完成了这个练习并找到了7个特征,这已经很不错了。
Weka 里的选择属性一栏有一个非常棒的函数,它会建议你选择那些特征来训练:
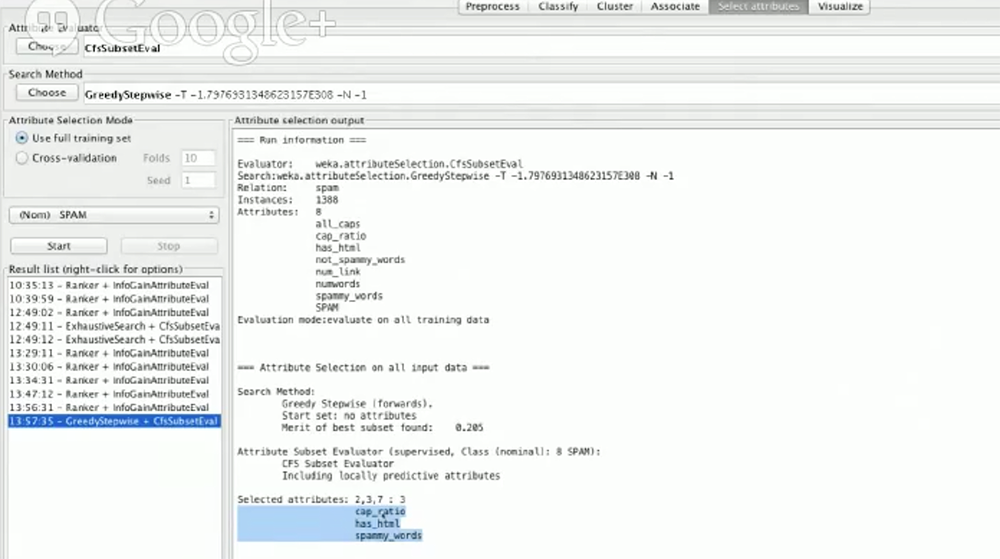
正如你看到的,它推荐我们使用 cap_ratio,has_html,以及 spammy_words 3个特征。因此如果我们在预处理栏不选择其他的特征,然后进行测试准确率,我们可能也会得到近似于 86% 的结果。
我鼓励你们根据所学实现你们自己的特征,然后看看是否提高了分类准确率。我希望这次练习对你们开始学习机器学习和自然语言处理是有帮助的。
打赏支持我翻译更多好文章,谢谢!
打赏译者
打赏支持我翻译更多好文章,谢谢!

评论关闭