可视化图的基本算法,可视化图算法,未经作者许可,禁止转载!
可视化图的基本算法,可视化图算法,未经作者许可,禁止转载!
本文作者: 编橙之家 - Yusheng 。未经作者许可,禁止转载!欢迎加入编橙之家 专栏作者。
0. About
关于图的基本表示与基本算法,包括图的邻接表和邻接矩阵表示法;图的广度优先(BFS)与深度优先(DFS)搜索算法;最小权生成树问题的 Kruskal 算法与 Prim 算法;单源最短路径的 Dijkstra 算法。
1. 邻接表与邻接矩阵表示
邻接表表示法就是将图的每个节点保存在数组中,每个节点指向与之相邻的节点所组成的链表:
class GraphTable:
def __init__(self, nodes, edges, is_dir = False):
self.nodes = nodes
self.edges = edges
self.is_dir = is_dir
self.graph = []
for node in nodes:
self.graph.append([node])
for edge in edges:
for n in self.graph:
if n[0] == edge[0]:
n.append(edge[1])
if not is_dir:
if n[0] == edge[1]:
n.append(edge[0])
self.G = None
def __str__(self):
return 'n'.join([str(n) for n in self.graph])
def draw(self):
settings = dict(name='Graph', engine='circo', node_attr=dict(shape='circle'), format='png')
self.G = Digraph(**settings) if self.is_dir else Graph(**settings)
for node in self.nodes:
self.G.node(str(node), str(node))
for edge in self.edges:
self.G.edge(str(edge[0]), str(edge[1]))
return self.G
gt = GraphTable([1,2,3,4,5], [(1,2), (1,5), (2,5), (2,4), (5,4), (2,3), (3,4)]) print(gt) gt.draw() """ [1, 2, 5] [2, 1, 5, 4, 3] [3, 2, 4] [4, 2, 5, 3] [5, 1, 2, 4] """
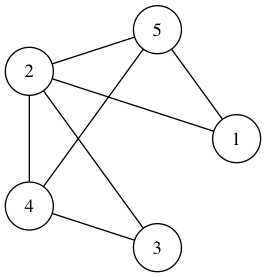
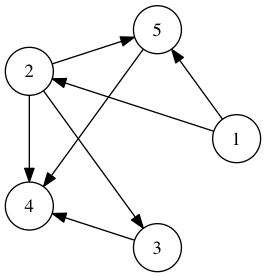
dgt = GraphTable([1,2,3,4,5], [(1,2), (1,5), (2,5), (2,4), (5,4), (2,3), (3,4)], is_dir=True) print(dgt) dgt.draw() """ [1, 2, 5] [2, 5, 4, 3] [3, 4] [4] [5, 4] """
邻接矩阵表示法则是用一个 N 阶矩阵来表示,其中任意两个节点所对应的矩阵中的值为0或1表示两个节点是否相连通:
class GraphMatrix:
def __init__(self, nodes, edges, is_dir=False):
self.nodes = nodes
self.edges = edges
self.graph = []
for _ in range(len(nodes)):
self.graph.append([0]*len(nodes))
for (x, y) in edges:
self.graph[x-1][y-1] = 1
if not is_dir:
self.graph[y-1][x-1] = 1
def __str__(self):
return str('n'.join([str(i) for i in self.graph]))
gm = GraphMatrix([1,2,3,4,5], [(1,2), (1,5), (2,5), (2,4), (5,4), (2,3), (3,4)]) print(gm) """ [0, 1, 0, 0, 1] [1, 0, 1, 1, 1] [0, 1, 0, 1, 0] [0, 1, 1, 0, 1] [1, 1, 0, 1, 0] """
dgm = GraphMatrix([1,2,3,4,5], [(1,2), (1,5), (2,5), (2,4), (5,4), (2,3), (3,4)], is_dir=True) print(dgm) """ [0, 1, 0, 0, 1] [0, 0, 1, 1, 1] [0, 0, 0, 1, 0] [0, 0, 0, 0, 0] [0, 0, 0, 1, 0] """
这两种表示方法都可以很容易地扩展为加权图,对于比较稀疏的图(定点数远大于边的数量)通常采用邻接表表示法,后面涉及到的算法均采用邻接表表示法。
2. 广度优先搜索与深度优先搜索
广度优先搜索就是按层遍历树时用到的思想,即先尽可能多地访问直接相连的节点,再向深处延伸,因此需要使用队列存储访问过的节点。
# 定义一个枚举类型,用于标记访问过的节点的状态
# WHITE 表示未查看过
# GRAY 表示查看过但未访问
# BLACK 表示已经访问过
import enum
class Color(enum.Enum):
WHITE = 0
GRAY = 1
BLACK = 2
# 需要向 GraphTable 添加方法 adjs 用于
# 查询所有与某节点直接相连的节点
def adjs(self, node):
return list(filter(lambda n: n[0] == node, self.graph))[0][1:]
def BFS(G, s):
color = {}
dists = {}
parent= {}
for node in G.graph:
color[node[0]] = Color.WHITE
dists[node[0]] = -1
parent[node[0]]= None
color[s] = Color.GRAY
dists[s] = 0
queue = [s]
while len(queue):
cursor = queue.pop(0)
for v in G.adjs(cursor):
if color[v] == Color.WHITE:
color[v] = Color.GRAY
dists[v] = dists[cursor] + 1
parent[v] = cursor
queue.append(v)
color[cursor] = Color.BLACK
print("[{}] visited!".format(cursor))
return parent
返回的 parent 保存了每个被访问节点的上一个节点,可以通过递归找出访问路径:
def shortest_path(G, s, v, visit, search = BFS):
parent = search(G, s)
print(parent)
def visit_path(parent, s, v, visit):
if v == s:
visit(s)
elif parent[v] is None:
print("No path from {} to {}".format(s, v))
else:
visit_path(parent, s, parent[v], visit)
visit(v)
visit_path(parent, s, v, visit)
path = []
shortest_path(gt, 1, 3, path.append)
print(path)
"""
[1] visited!
[2] visited!
[5] visited!
[4] visited!
[3] visited!
[1, 2, 3]
"""
深度优先搜索则是先尽可能深远地搜索每一个相连通的节点,因此可以使用栈结构或递归的方式进行搜索:
def DFS(G, s, visit=print):
color = {}
for node in G.graph:
color[node[0]] = Color.WHITE
def DFS_visit(node):
color[node] = Color.GRAY
for v in G.adjs(node):
if color[v] == Color.WHITE:
DFS_visit(v)
color[node] = Color.BLACK
visit("[{}] visited!".format(node))
DFS_visit(s)
DFS(gt, 1)
"""
[3] visited!
[4] visited!
[5] visited!
[2] visited!
[1] visited!
"""
3. 最小生成树
最小生成树实际上是“最小权值生成树”的缩写,与后面的单源最短路径问题一样,都是基于加权图的算法,因此需要先定义加权图的邻接表表示法:
# 加权图
class WeiGraph(GraphTable):
def __init__(self, nodes, edges, is_dir=False):
self.nodes = nodes
self.edges = edges
self.graph = []
for node in nodes:
self.graph.append([(node, 0)])
for (x, y, w) in edges:
for n in self.graph:
if n[0][0] == x:
n.append((y, w))
if not is_dir:
if n[0][0] == y:
n.append((x, w))
self.G = None
self.is_dir = is_dir
def adjs(self, node):
return list(filter(lambda n: n[0][0] == node, self.graph))[0][1:]
def draw(self, color_filter=None):
if color_filter is None:
color_filter = lambda edge: 'black'
settings = dict(name='Graph', engine='circo', node_attr=dict(shape='circle'))
self.G = Graph(**settings) if not self.is_dir else Digraph(**settings)
for node in self.nodes:
self.G.node(str(node), str(node))
for (x, y, w) in self.edges:
self.G.edge(str(x), str(y), label=str(w), color=color_filter((x, y, w)))
return self.G
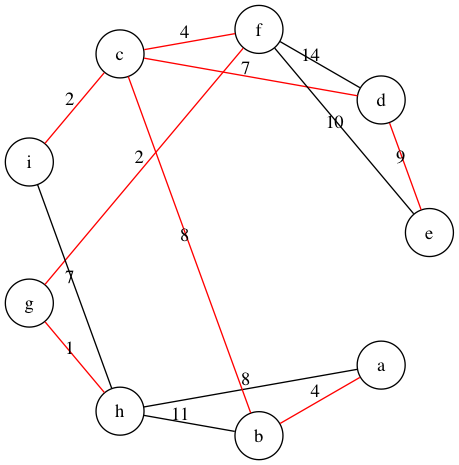
wg = WeiGraph('abcdefghi', [('a','b',4), ('a','h',8),
('b','h',11),('b','c',8),
('c','d',7), ('c','f',4), ('c','i',2),
('d','e',9), ('d','f',14),
('e','f',10),
('f','g',2),
('g','h',1),
('h','i',7)])
print(wg)
"""
[('a', 0), ('b', 4), ('h', 8)]
[('b', 0), ('a', 4), ('h', 11), ('c', 8)]
[('c', 0), ('b', 8), ('d', 7), ('f', 4), ('i', 2)]
[('d', 0), ('c', 7), ('e', 9), ('f', 14)]
[('e', 0), ('d', 9), ('f', 10)]
[('f', 0), ('c', 4), ('d', 14), ('e', 10), ('g', 2)]
[('g', 0), ('f', 2), ('h', 1)]
[('h', 0), ('a', 8), ('b', 11), ('g', 1), ('i', 7)]
[('i', 0), ('c', 2), ('h', 7)]
"""
wg.draw()
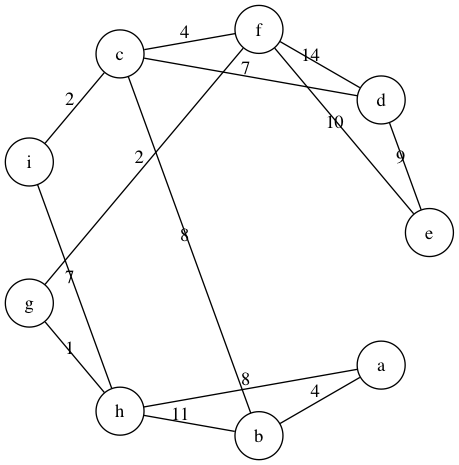
最小生成树问题是指在给定的加权图中选择部分边,满足所有节点可以互相连通(即可以生成原有的图)同时所有边的权值之和最小。
Kruskal 算法首先将所有节点看作是一群孤立的树(即森林),然后将所有边按照权值存入优先队列,之后依次取出权值最小的边,并检查这个边的两个节点是否已经在同一棵树上,如果不是则将两点所在树合二为一。这里的森林和树通过集合进行操作。
# 优先队列采用 Python 的 Queue.PriorityQueue
# 但由于图的边采用 (u, v, w) 的方式存储
# 而 PriorityQueue 只以第一个元素作为权值
# 因此需要稍作改动
from queue import PriorityQueue as PQ
class PriorityQueue(PQ):
def __init__(self, *option):
super().__init__(*option)
def put(self, item):
super().put(item[::-1])
def get(self):
return super().get()[::-1]
# 用 集合 存储和操作森林与树
class Forest:
def __init__(self):
self.sets = set()
def make(self, item):
self.sets.add(frozenset({item}))
def union(self, item_a, item_b):
a = self.find(item_a)
b = self.find(item_b)
self.sets.remove(a)
self.sets.remove(b)
self.sets.add(a.union(b))
def find(self, item):
for s in self.sets:
if s.issuperset(frozenset({item})):
return s
return None
# Kruskal 算法
def Kruskal(G):
Tree = set()
all_nodes = Forest()
for node in G.nodes:
all_nodes.make(node)
queue = PriorityQueue()
for edge in G.edges:
queue.put(edge)
while not queue.empty():
(u, v, w) = queue.get()
if all_nodes.find(u) != all_nodes.find(v):
Tree = Tree.union({(u, v, w)})
all_nodes.union(u, v)
return list(Tree)
tree = Kruskal(wg)
print(tree)
"""
[('b', 'c', 8), ('c', 'i', 2), ('g', 'h', 1), ('d', 'e', 9), ('c', 'f', 4), ('c', 'd', 7), ('f', 'g', 2), ('a', 'b', 4)]
"""
对结果中的边进行染色标记:
def cf(tree):
def color_filter(edge):
in_tree = filter(lambda t: t[:2] == edge[:2] or t[:2][::-1] == edge[:2],tree)
if len(list(in_tree)) > 0:
return 'red'
return 'black'
return color_filter
wg.draw(color_filter=cf(tree))
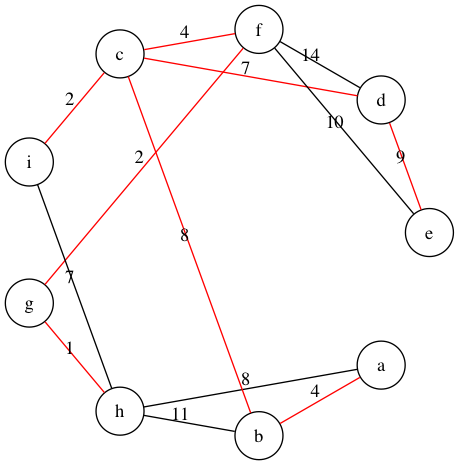
Prim 算法与后面的 Dijkstra 算法有些类似,保存一个 k[node] 为 node 与最小生成树中所有节点之间最小权值,然后从起点开始,以 k[node] 为键存入优先队列,然后从队列中依次取出的最小元素,找到与树外相邻节点的最小权值,并将其纳入树中。
这里为区分树内树外可以直接检查优先队列,Python 中的优先队列实际上就是对最小堆的简单封装,本质上还是一个列表,因此我们可以直接利用 heapq 进行改造获得一个可查询的优先队列:
from heapq import heappush, heappop, heapify
class SearchQueue:
def __init__(self):
self.queue = []
def put(self, item):
heappush(self.queue, item)
def get(self):
return heappop(self.queue)
def contains(self, item):
return len(list(filter(lambda e: e[1] == item, self.queue)))
def empty(self):
return len(self.queue) == 0
def update(self, item):
for i in self.queue:
if i[1] == item[1]:
i[0] == item[0]
break
heapify(self.queue)
def Prim(G, r):
INF = float('inf')
k = {} # 保存权值
p = {} # 保存上一个节点
queue = SearchQueue()
for node in G.nodes:
k[node] = INF
p[node] = None
k[r] = 0
for node in G.nodes:
queue.put((k[node], node))
while not queue.empty():
cur = queue.get()
for (node, w) in G.adjs(cur[1]):
if queue.contains(node) and w
parent = Prim(wg, 'a')
print(parent)
"""
{'a': None,
'b': 'a',
'c': 'b',
'd': 'c',
'e': 'd',
'f': 'c',
'g': 'f',
'h': 'g',
'i': 'c'}
"""
返回结果为一颗父指针树,也可以基于此对边进行染色:
def cf(parent):
def color_filter(edge):
if parent.get(edge[0]) == edge[1] or parent.get(edge[1]) == edge[0]:
return 'red'
return 'black'
return color_filter
wg.draw(color_filter=cf(parent))
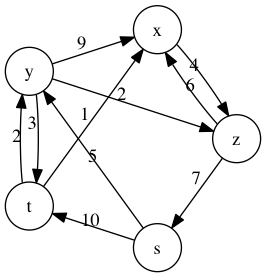
4. 单源最短路径问题
单源最短路径问题是指从给定节点出发到剩余所有节点的加权最短路径,以加权有向图为例:
dwg = WeiGraph('stxyz', [('s','t',10),('s','y',5),
('t','x',1),('t','y',2),
('x','z',4),
('y','t',3),('y','x',9),('y','z',2),
('z','s',7),('z','x',6)], is_dir=True)
print(dwg)
"""
[('s', 0), ('t', 10), ('y', 5)]
[('t', 0), ('x', 1), ('y', 2)]
[('x', 0), ('z', 4)]
[('y', 0), ('t', 3), ('x', 9), ('z', 2)]
[('z', 0), ('s', 7), ('x', 6)]
"""
dwg.draw()
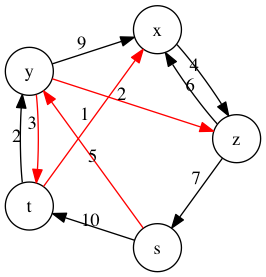
Dijkstra 算法同样从起点开始构建最短路径,将所有节点与最短路径之间的距离作为键值存入优先队列,依次选择队列中的最小值,并与所有邻接点进行比较,看是否通过该点将其纳入最短路径是权值最小的:
def Dijkstra(G, s):
INF = float('inf')
dist = {}
parent = {}
for node in G.nodes:
dist[node] = INF
parent[node] = None
dist[s] = 0
queue = SearchQueue()
for node in G.nodes:
queue.put((dist[node], node))
while not queue.empty():
cur = queue.get()
for (node, w) in G.adjs(cur[1]):
if dist[node] > dist[cur[1]] + w:
dist[node] = dist[cur[1]] + w
parent[node] = cur[1]
queue.update((dist[node], node))
return parent
parent = Dijkstra(dwg, 's')
print(parent)
"""
{'s': None, 't': 'y', 'x': 't', 'y': 's', 'z': 'y'}
"""
def cf(parent):
def color_filter(edge):
if parent.get(edge[1]) == edge[0]: # 有向
return 'red'
return 'black'
return color_filter
dwg.draw(color_filter=cf(parent))
打赏支持我写出更多好文章,谢谢!
打赏作者
打赏支持我写出更多好文章,谢谢!

相关内容
- Python算法:基础知识,python算法基础知识, 1.计算模型
- Python编写的最短路径算法,python编写最短,未经作者许可
- python实现堆排序算法代码,python堆排序算法,python 实现
- Python插入排序和堆排序,python排序堆排序,插入排序,它
- Python 模拟竖式大数乘法,python竖式大数乘法,python内置
- python解决八皇后算法,python皇后算法,python解决经典算法
- python实现逆波兰计算表达式,python波兰表达式,逆波兰表
- python实现希尔排序算法,python希尔算法,希尔排序(Shel
- python求两序列的和最小差值序列,python最小差值序列
- python实现Bogo排序算法,pythonbogo排序,Bogo算法定义下面是
评论关闭