Scrapy+Flask+Mongodb+Swift开发全攻略(2),scrapyflask,第一件事是找到spide
Scrapy+Flask+Mongodb+Swift开发全攻略(2),scrapyflask,第一件事是找到spide
好的,这期开始之前,我们先要干两件事。第一件事是找到spiders文件夹里的dbmeizi_scrapy.py。打开他,上一篇教程里,这个爬虫文件是这么写的。
def parse(self, response):
liResults = Selector(response).xpath('//li[@class="span3"]')
for li in liResults:
for img in li.xpath('.//img'):
item = MeiziItem()
item['title'] = img.xpath('@data-title').extract()
item['dataid'] = img.xpath('@data-id').extract()
item['datasrc'] = img.xpath('@data-src').extract()
item['startcount'] = 0
yield item
现在我们需要改成这样.
Python
def parse(self, response):
liResults = Selector(response).xpath('//li[@class="span3"]')
for li in liResults:
for img in li.xpath('.//img'):
item = MeiziItem()
item['title'] = img.xpath('@data-title').extract()[0]
item['dataid'] = img.xpath('@data-id').extract()[0]
item['datasrc'] = img.xpath('@data-src').extract()[0]
item['startcount'] = 0
yield item
why?
很简单,因为用extract这个方法得到的是一个数组,而我们的每一个字段实际上是一个string而非一个array,如果不取第一个值,那么存入mongodb之后,title这个key对应的value是一个数组,这会导致我们将mongodb里的数据转换成json之后需要在客户端再进行分解。很麻烦。
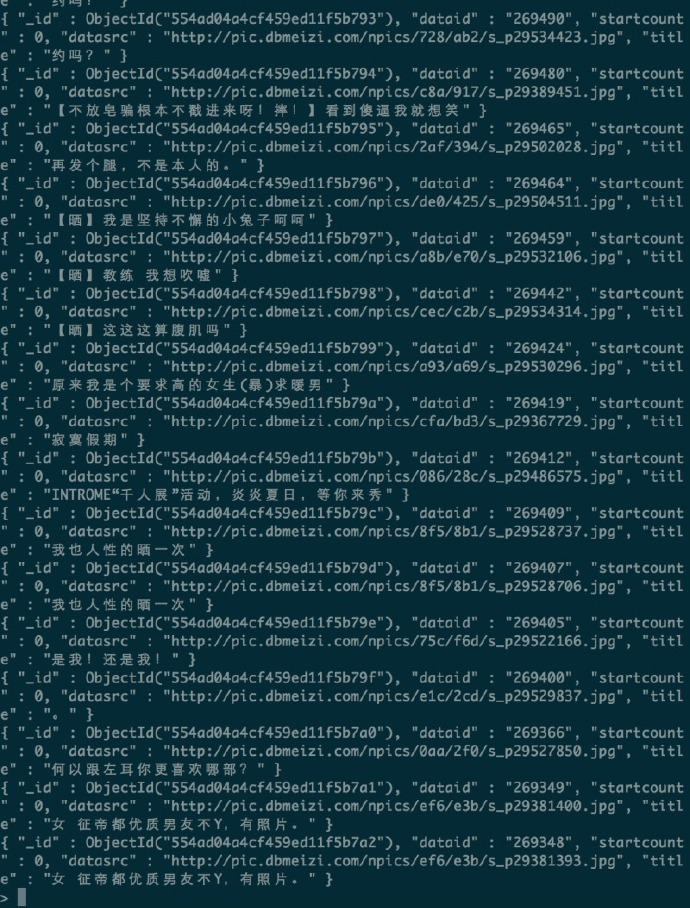
第二件事,是删除我们上一个爬虫爬取的数据。
如图:
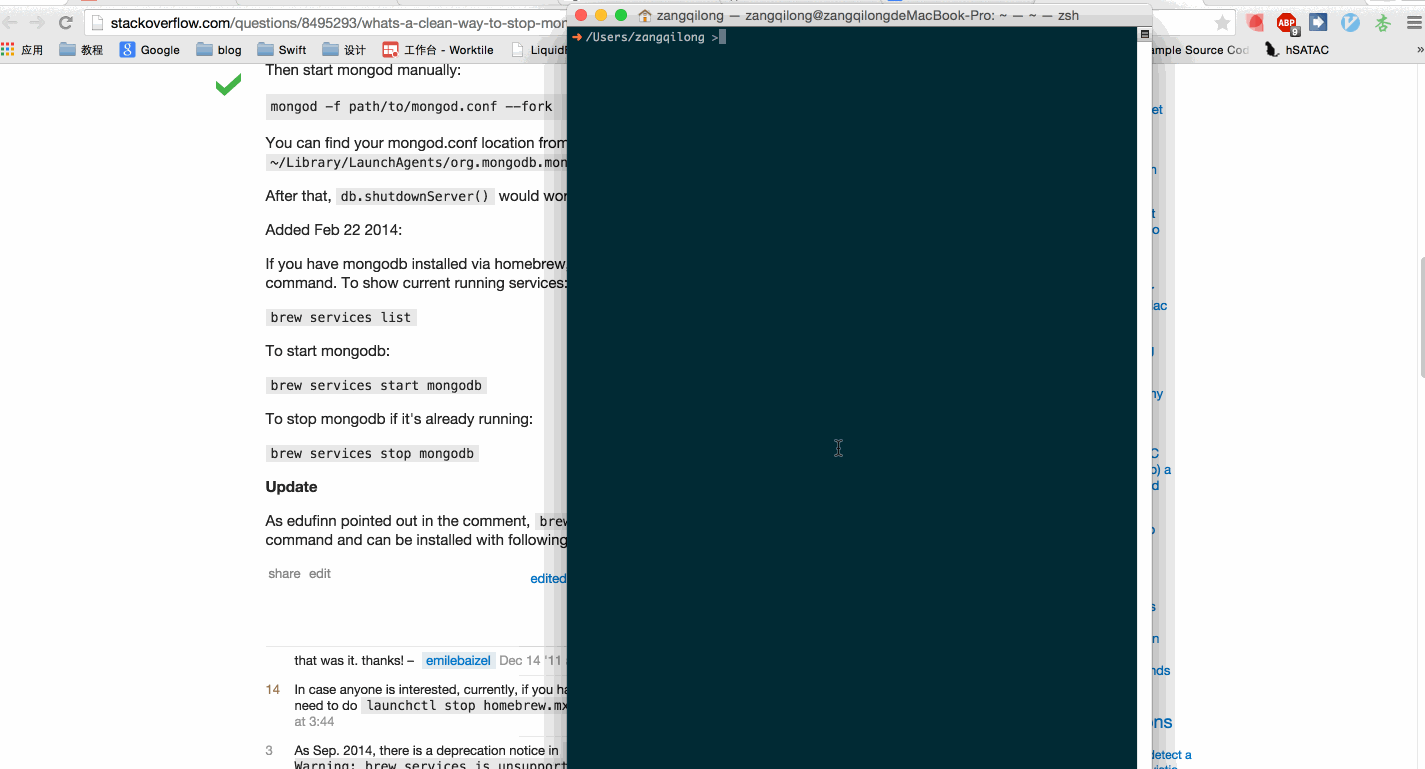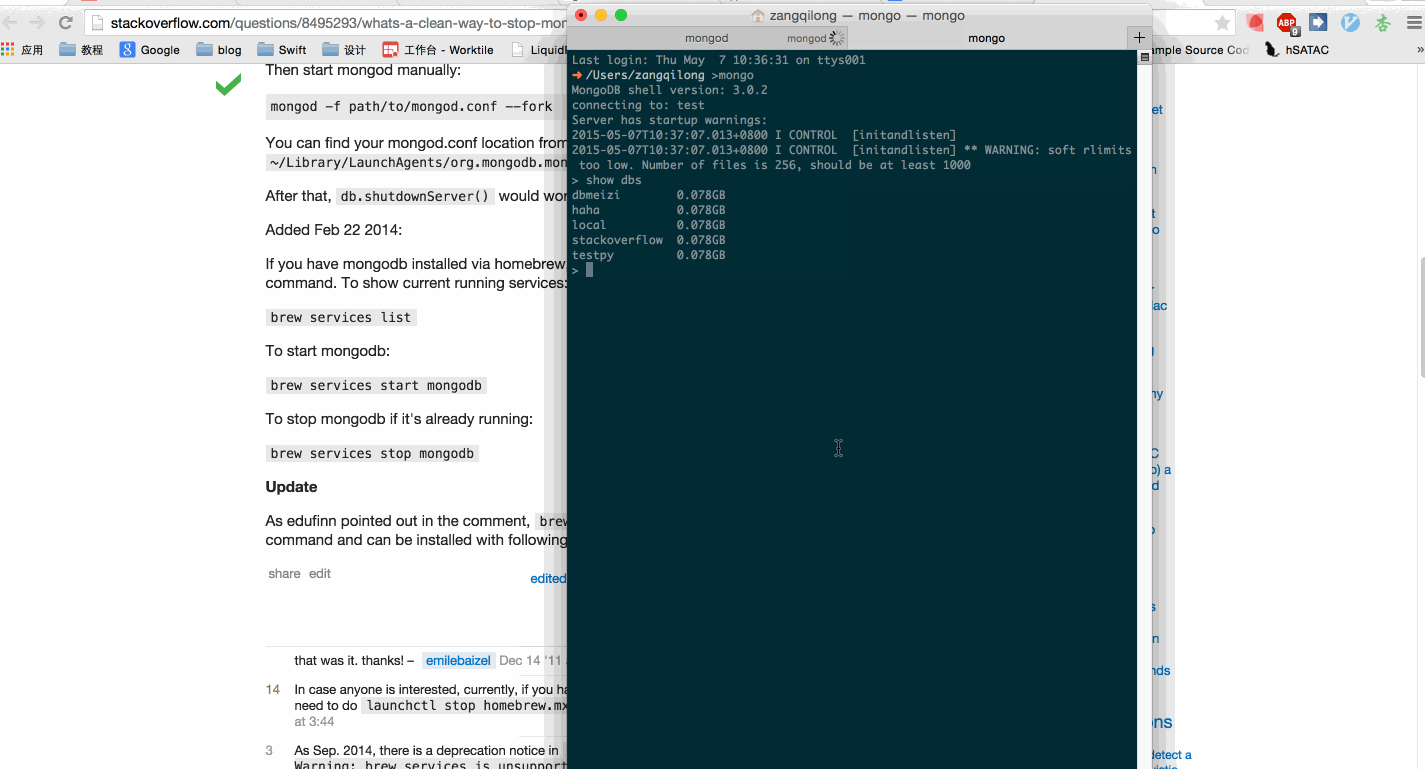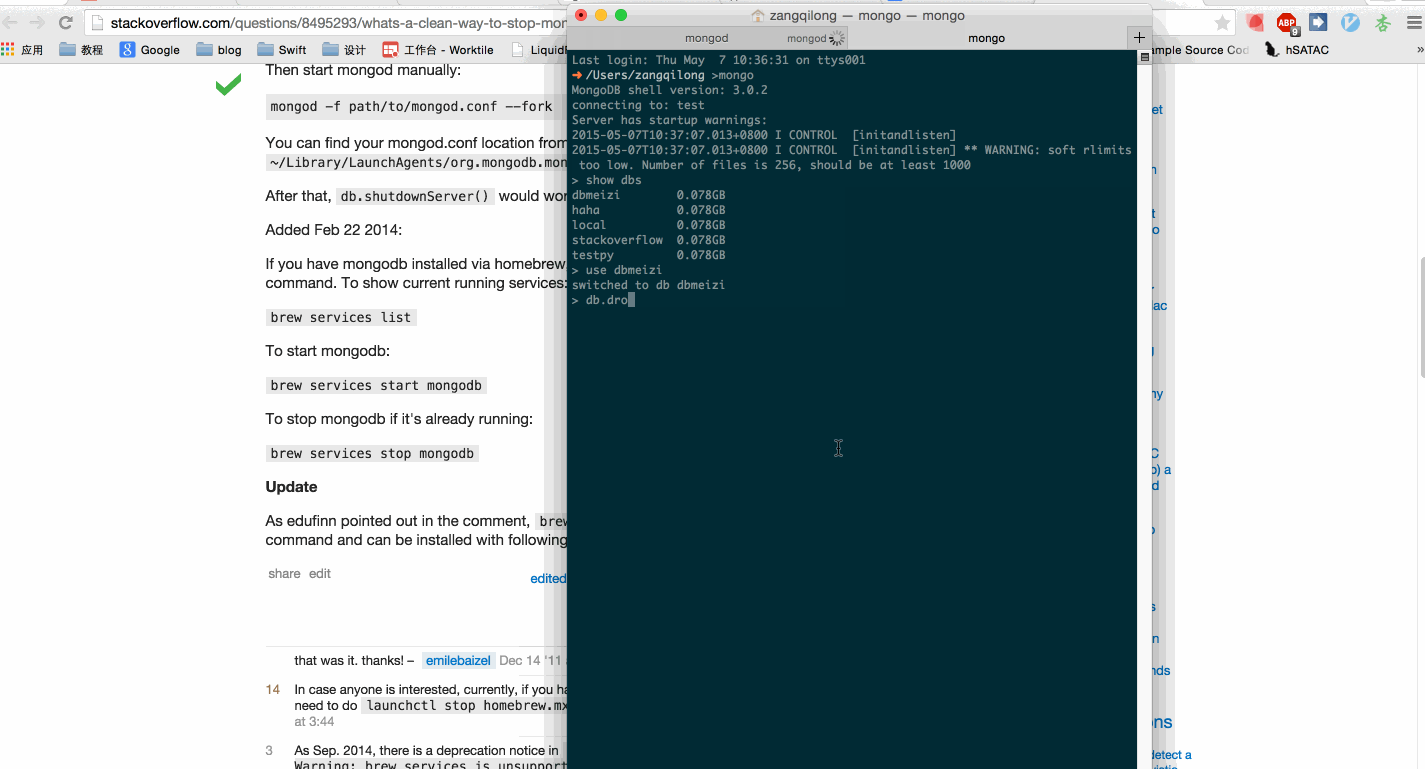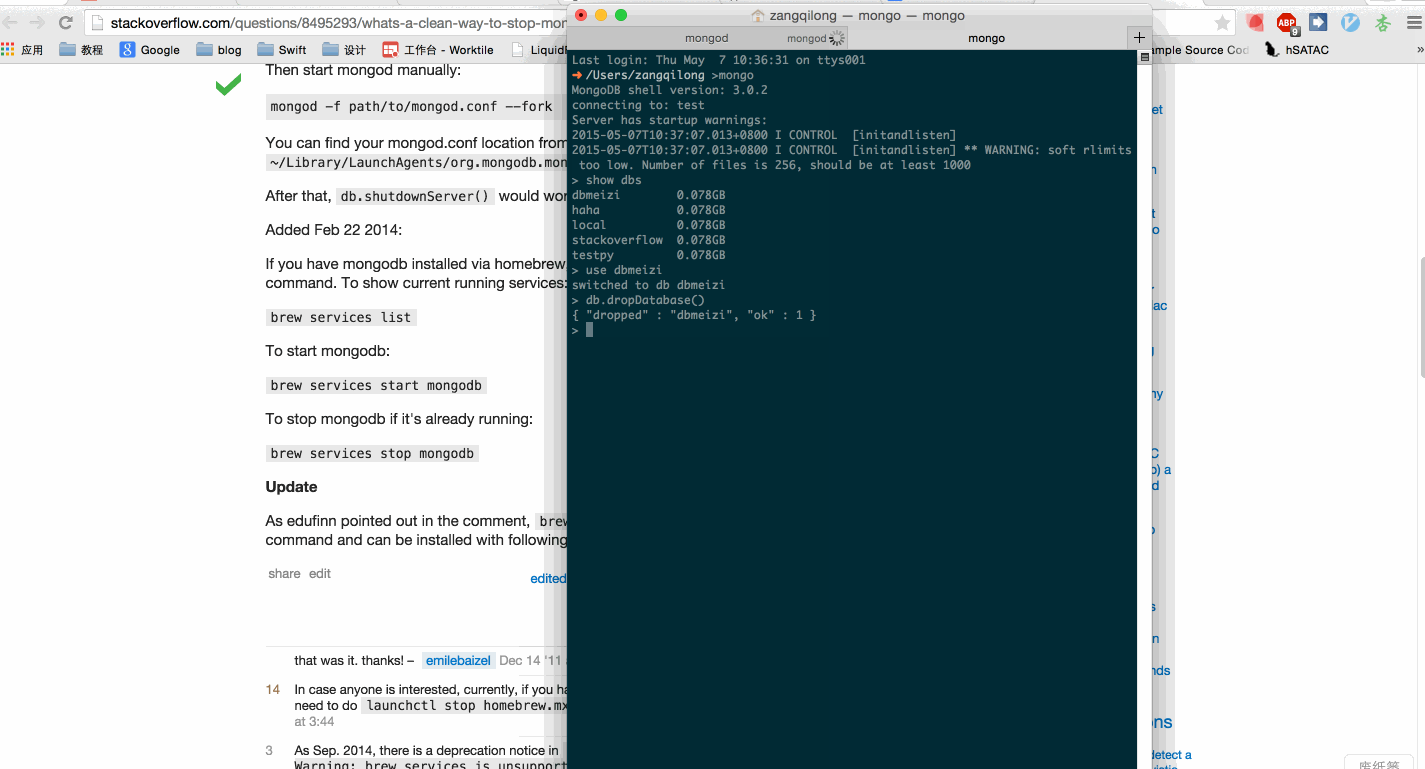
ok,重新运行我们的爬虫,scrapy crawl dbmeiziSpider,现在,check一下数据库里的内容,是不是以前的每个字段对应的内容已经从数组变成了string了。
开始编写服务器
激动人心的时刻要开始了,我们要从iOS程序员变成一个菜鸟级别的server端选手。不过能用自己编写的iOS客户端从自己写的server下载数据,也挺爽的,不是么?
在编写服务器端的时候确保你用pip安装了下面几个库。
1.pymongo
2.Flask
我们的服务端代码如下。
Python
from flask import Flask, request
import json
from bson import json_util
from bson.objectid import ObjectId
import pymongo
app = Flask(__name__)
mongoClient = pymongo.MongoClient('localhost', 27017)
db = mongoClient['dbmeizi']
def toJson(data):
return json.dumps(data, default=json_util.default)
@app.route('/meizi/', methods=['GET'])
def findmeizi():
if request.method == 'GET':
lim = int(request.args.get('limit', 10))
off = int(request.args.get('offset'),0)
results = db['meizi'].find().skip(off).limit(lim)
json_results= []
for result in results:
json_results.append(result)
return toJson(json_results)
if __name__ == '__main__':
app.run(debug=True)
以上代码就是我们的服务端代码,只有短短28行,python的强大之处也在于此。
好的,我来一行一行的解释一下。
前面5行就是import各种我们需要的库,如果后面你使用python server.py运行的时候提示错误,很可能是你的机子上缺少上述的库。
app = Flask(__name__)这句话就是利用Flask的构造方法生成一个Flask实例,name是什么?简单来说,你创建的任何python文件(.py),都会有一个内置属性,叫做__name__,他有两个用途,如果你在命令行状态下直接运行的时候,这个时候这个python文件里的__name__就是__main__,如果你是在别的python文件里import *.py,那么这个name的东西就是这个Python文件的文件名。so,这个东西常常用来判断,你是在import还是直接在命令行里运行这个文件。python .py
所以,上一行,我们生成了一个Flask实例并且把这个实例赋给了app这个变量。
Python
mongoClient = pymongo.MongoClient('localhost', 27017)
db = mongoClient['dbmeizi']
这两句很简单,就是用pymongo这个第三方库,打开我们的mongodb数据库,并且拿到我们的dbmeizi这个database。
Python
def toJson(data):
return json.dumps(data, default=json_util.default)
这句话,我们定义了一个函数,用来把mongodb里的数据转换为json格式。用来返回给我们的ios客户端。
@app.route('/meizi/', methods=['GET'])
这句话的意思就是Flask的一种写法,意思就是当我们发起了一个request,并且这个request的方法是get,url是"localhost:5000/meizi/"这种的的时候,我们就执行findmeizi()这个方法。
def findmeizi():
if request.method == 'GET':
lim = int(request.args.get('limit', 10))
off = int(request.args.get('offset'),0)
results = db['meizi'].find().skip(off).limit(lim)
json_results= []
for result in results:
json_results.append(result)
return toJson(json_results)
这个方法就是我们的http server监测到用户发起get请求,并且URL是形如’http://127.0.0.1:5000/sightings/?offset=0&limit=3’的时候,我们取出limit这个值,赋给lim这个变量,然后取出offset这个值,赋给off。
然后呢?利用我们的db(就是刚才利用pymongo获取的mongodb实例),取出‘meizi’这个collection,skip(off)的意思就是跳过前面多少行,limit(lim)表示从数据库取出多少个值。
整句话的意思就是,从meizi这个collection里跳过前off个值,取后面的lim个值。
现在取到的数据都在results变量里,我们遍历results,放入json_results这个数组里,然后把数组转换成json格式返回给客户端。
我们运行一下试试。
python server.py
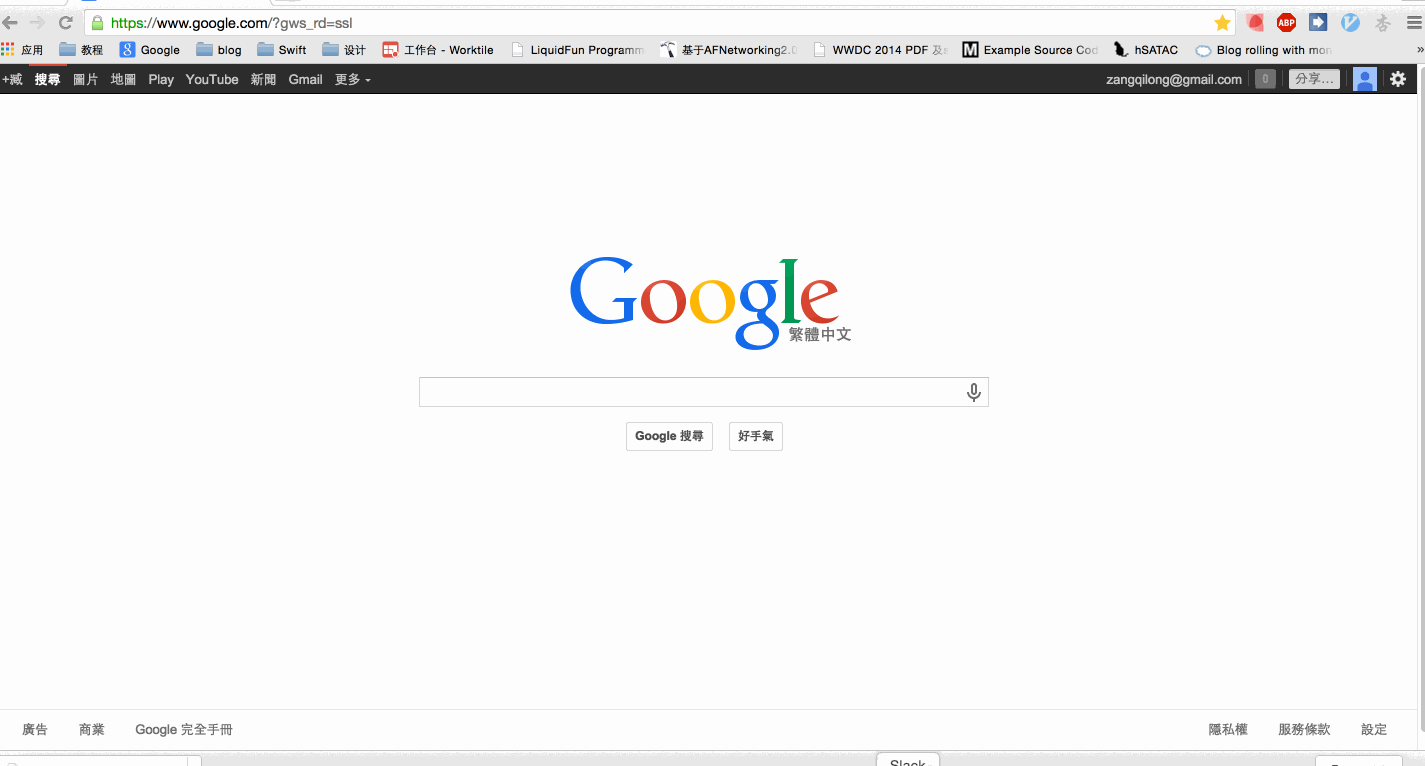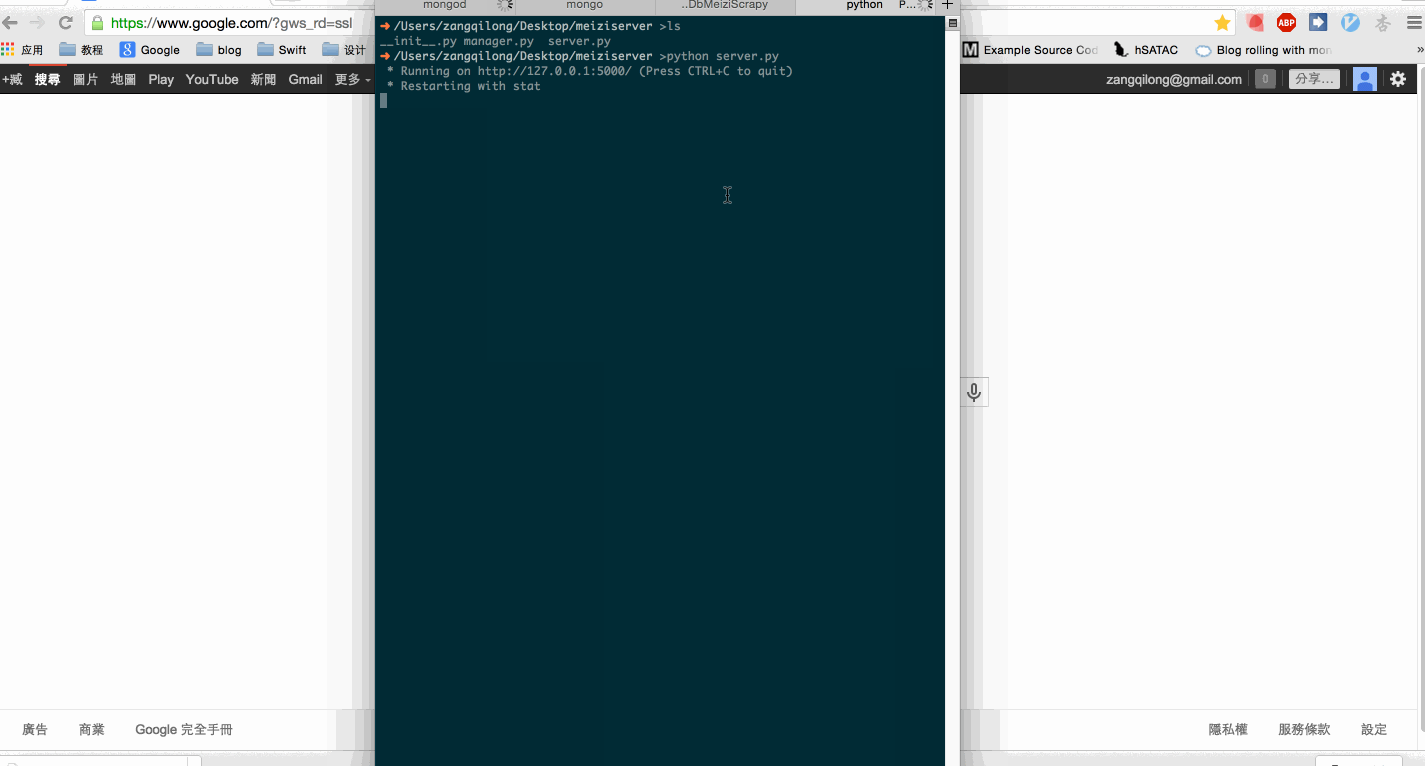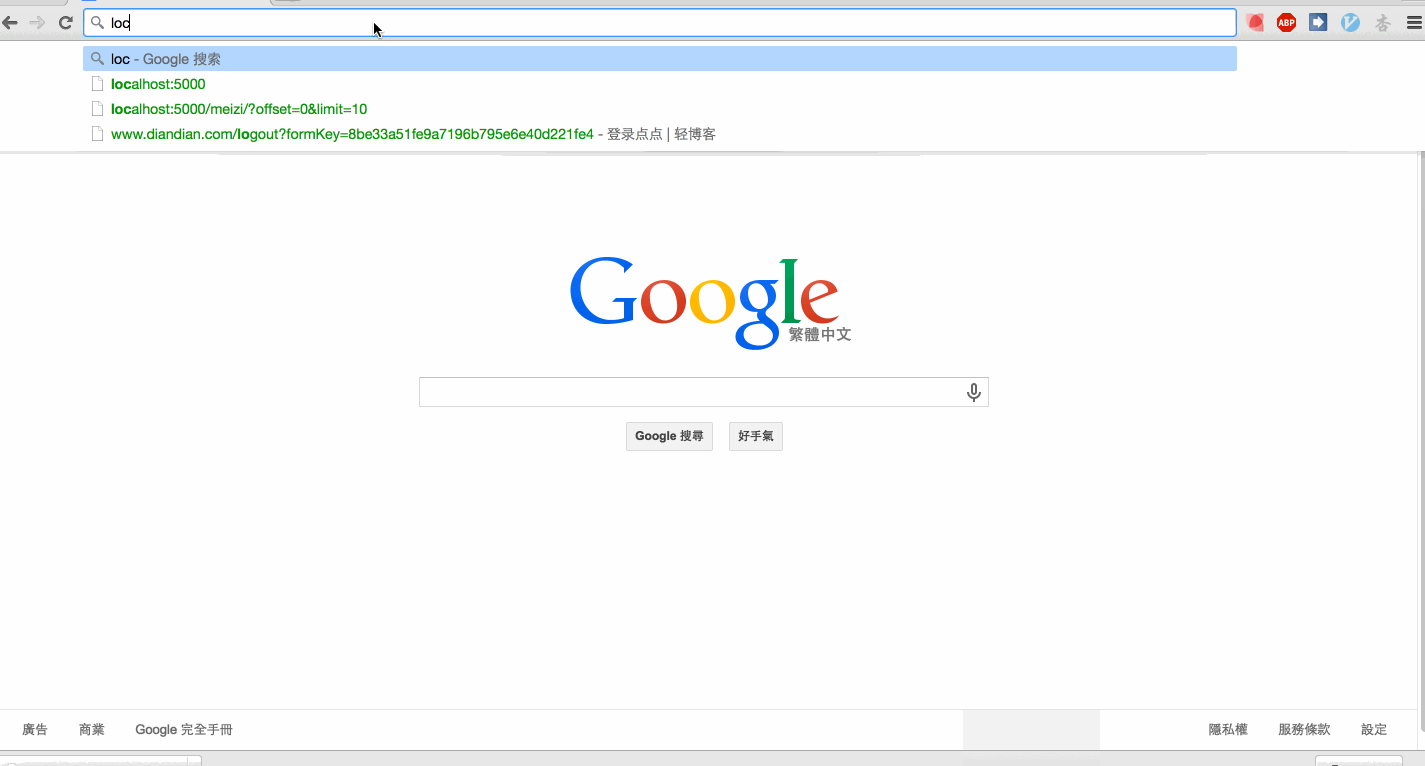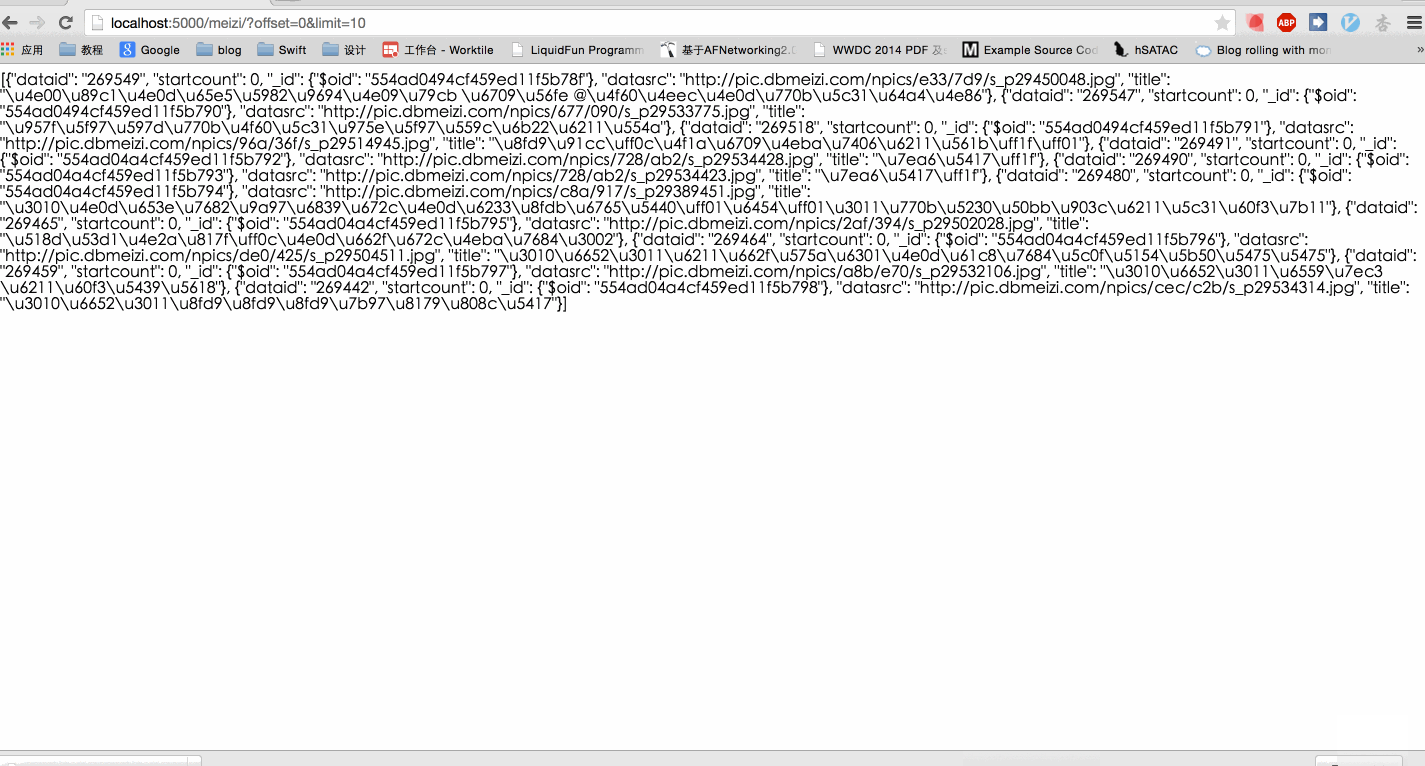
perfect!
数据已经返回给浏览器了。
这时候我们编写一个简单的iOS客户端,验证一下。
我们建立一个swift的iOS程序,用cocoapods安装下列库。
Pythonplatform :ios, '8.0' use_frameworks! target 'HotGirls' do pod 'Alamofire' pod 'Kingfisher' end target 'HotGirlsTests' do endPython
注意,cocoapods务必升级到最新版,要不然安装swift的第三方库会出现问题。
我写了一个超简单的iOS客户单,纯验证下服务端是否有效。
class ViewController: UIViewController {
@IBOutlet weak var mTableView: UITableView!
var imageURLStringArray:NSMutableArray = NSMutableArray()
override func viewDidLoad() {
super.viewDidLoad()
Alamofire.request(.GET, "http://localhost:5000/meizi/?offset=0&limit=10")
.responseJSON { (_, _, JSON, _) in
let resultArray:NSArray = JSON as! NSArray
for dict in resultArray{
self.imageURLStringArray.addObject(dict["datasrc"] as! String)
}
print(self.imageURLStringArray)
self.mTableView.reloadData()
}
// Do any additional setup after loading the view, typically from a nib.
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
Python
extension ViewController:UITableViewDelegate, UITableViewDataSource{
func tableView(tableView: UITableView, cellForRowAtIndexPath indexPath: NSIndexPath) -> UITableViewCell {
var cell:ImageTableViewCell = tableView.dequeueReusableCellWithIdentifier("ImageViewCellID") as! ImageTableViewCell
var imageURL:NSString = imageURLStringArray[indexPath.row] as! NSString
cell.meiziImageView.kf_setImageWithURL(NSURL(string: imageURL as String)!)
return cell
}
func tableView(tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return imageURLStringArray.count
}
func tableView(tableView: UITableView, heightForRowAtIndexPath indexPath: NSIndexPath) -> CGFloat {
return 250.0
}
运行一下。

哈哈,大功告成。数据返回正确。
github地址:https://github.com/zangqilong198812/MeiziServer
但是,这样就结束了么?
远远没有,爬虫完全是个半成品,服务端简直就是个玩笑,客户端什么炫酷特效交互都没有,做这样的东西简直是打自己的脸。
现在,万里长征只开始了一小步。
1.爬虫如何自己定时运行?
2.Mongodb如何避免插入重复数据?
3.Server如何提供多个接口。
4.如何Put,delete,Post,Get
5.POP,AsyncDisplaykit,collectionviewlayout,Custom Transition,Bézier curve,Private Cocoapods,Continuous integration,Unit Test.
现在,到了我展现真正实力的时候了。

相关内容
- Scrapy+Flask+Mongodb+Swift开发全攻略(3),scrapyflask, 那么我
- 这不是魔法:Flask和@app.route(2),flask@app.route,未经许
- 用Flask实现视频数据流传输,flask视频数据流,未经许可
- flask 源码解析:响应,flask源码解析响应, The return
- flask 源码解析:上下文,flask源码,只有像Add这种简单的
- flask 源码解析:请求,flask源码解析请求, 可以看到,虽
- flask 源码解析:session,flasksession,session 可以看做
- 如何理解Nginx、uWSGI和Flask之间的关系?,nginxflask,不同
- Flask中的请求上下文和应用上下文,flask上下文,整个请
- 一个Flask应用运行过程剖析,flask应用剖析,这是一个很
评论关闭