python pyspark入门篇,pythonpyspark,一.环境介绍:1.安
python pyspark入门篇,pythonpyspark,一.环境介绍:1.安
一.环境介绍:
1.安装jdk 7以上
2.python 2.7.11
3.IDE pycharm
4.package:spark-1.6.0-bin-hadoop2.6.tar.gz
二.Setup
1.解压spark-1.6.0-bin-hadoop2.6.tar.gz 到目录D:\spark-1.6.0-bin-hadoop2.6
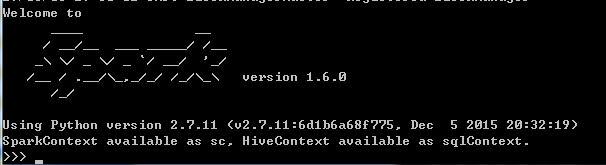
2.配置环境变量Path,添加D:\spark-1.6.0-bin-hadoop2.6\bin,此后可以在cmd端输入pySpark,返回如下则安装完成:
3.将D:\spark-1.6.0-bin-hadoop2.6\python下的pySpark文件拷贝到C:\Python27\Lib\site-packages
4.安装py4j , pip install py4j -i https://pypi.douban.com/simple
5.配置pychar环境变量:
三.Example
1.make a new python file:wordCount.py
#!/usr/bin/env python# -*- coding: utf-8 -*-import sysfrom pyspark import SparkContextfrom operator import addimport redef main(): sc = SparkContext(appName= "wordsCount") lines = sc.textFile(‘words.txt‘) counts = lines.flatMap(lambda x: x.split(‘ ‘)) .map( lambda x : (x, 1)) .reduceByKey(add) output = counts.collect() print output for (word, count) in output: print "%s: %i" %(word, count) sc.stop()if __name__ =="__main__": main()
2.代码中的words.txt如下:
The dynamic lifestylepeople lead nowadayscauses many reactions in our bodies and the one that is the most frequent of all is the headache
3.配置pycharm环境变量:
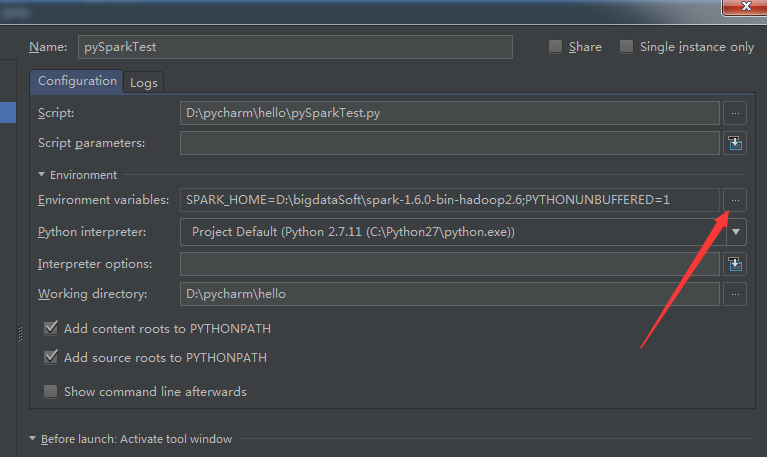
3.1 工具栏 run --> Edit configuration-->点击箭头位置
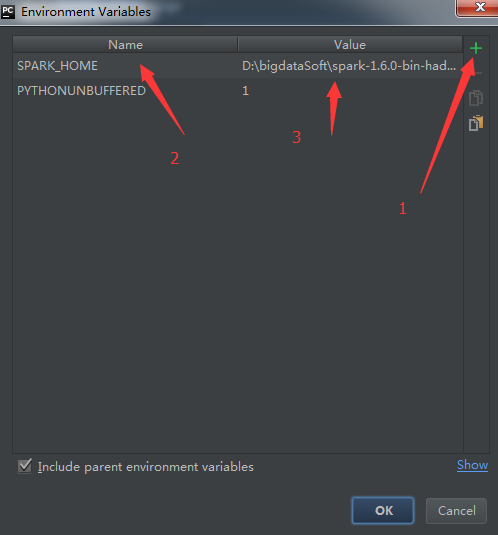
3.2 然后点击 + ,输入key:SPARK_HOME, value:D:\spark-1.6.0-bin-hadoop2.6
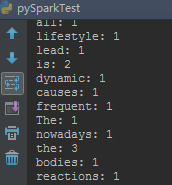
4.输出结果如下图:
四.深入练习:
1.文档:http://spark.apache.org/docs/latest/api/python/pyspark.html
2.在解压的Spark文档下,有example下有很多实例可以练习。D:\spark-1.6.0-bin-hadoop2.6\examples\src\main\python
python pyspark入门篇
相关内容
- 使用python操作InfluxDB,python操作influxdb,环境: CentOS
- 监控无线AP是否在线python脚本,监控appython脚本,由于工
- [python篇] [伯乐在线][1]永远别写for循环,python伯乐,首先
- python3.6执行pip3时 Unable to create process using '&q
- Python从2.7.5升级到3.6.5,python2.7.53.6.5,Python从2.7
- python正则表达式re 中m.group和m.groups的解释,m.groupm.gro
- python数据类型,,方法字符串:strt
- Python常用模块—— Colorama模块,pythoncolorama模块,简介
- 那些坑爹的python面试题,坑爹python,Python基础:说
- linux中python安装,linuxpython安装,1、查看当前环境中是
评论关闭