python 读取大文件越来越慢(判断 key 在 map 中,千万别用 in keys()),pythonkeys,背景:今天乐乐姐写代
python 读取大文件越来越慢(判断 key 在 map 中,千万别用 in keys()),pythonkeys,背景:今天乐乐姐写代
背景:
今天乐乐姐写代码,读取一个四五百兆的文件,然后做一串的处理。结果处理了一天还没有出来结果。问题出在哪里呢?
解决:
1. 乐乐姐打印了在不同时间点的时间,直接print time() 即可。发现一个规律,执行速度是越来越慢的。
2. 为什么会越来越慢呢?
1)可能原因1,GC 的问题,有篇文章里面写,python list append 的时候会越来越慢,解决方案是禁止GC:
使用 gc.disable()和gc.enable()
2)改完上面,仍然不行,然后看到一篇文章里面写,可能是因为 git 导致的,因为append 的时候 git 会不断同步,会出问题,于是删除 .git 文件夹,结果还是不行。
3)继续查询,发下一个及其有可能出问题的地方。dict 的 in dict.key(),判断 key 是否在 dict 里面,这个的效率是非常低的。看到一篇文章比较了效率:
① 使用 in dict.keys() 效率:
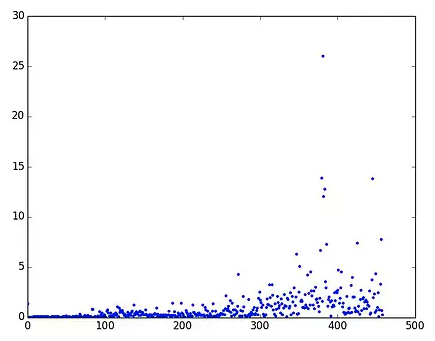
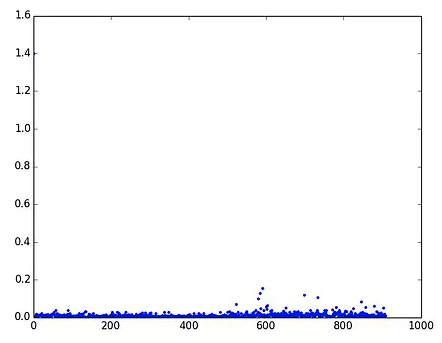 发现 has_key() 效率比较稳定。于是修改,问题解决。后话:最初的时候,的确是使用 has_key(), 结果后面上传代码的时候,公司代码检查过不了,提示不能使用这个函数,只能改成 in dict.key() 这种方式,为什么公司不让这么传呢?经过一番百度,发现原因所在:在 python3 中,直接将 has_key() 函数给删除了,所以禁止使用。那禁止了该怎么办呢?原来 python 中 in 很智能,能自动判断 key 是否在字典中存在。所以最正规的做法不是 has_key(), 更不是 in dict.keys(), 而是 in dict.
发现 has_key() 效率比较稳定。于是修改,问题解决。后话:最初的时候,的确是使用 has_key(), 结果后面上传代码的时候,公司代码检查过不了,提示不能使用这个函数,只能改成 in dict.key() 这种方式,为什么公司不让这么传呢?经过一番百度,发现原因所在:在 python3 中,直接将 has_key() 函数给删除了,所以禁止使用。那禁止了该怎么办呢?原来 python 中 in 很智能,能自动判断 key 是否在字典中存在。所以最正规的做法不是 has_key(), 更不是 in dict.keys(), 而是 in dict.附录:
in、 in dict.keys()、 has_key() 方法实战对比:
>>> a = {‘name‘:"tom", ‘age‘:10, ‘Tel‘:110}>>> a{‘age‘: 10, ‘Tel‘: 110, ‘name‘: ‘tom‘}>>> print ‘age‘ in aTrue>>> print ‘age‘ in a.keys()True>>>>>> print a.has_key("age")True参考资料:
https://www.douban.com/group/topic/44472300/
http://www.it1352.com/225441.html
https://blog.csdn.net/tao546377318/article/details/52160942
python 读取大文件越来越慢(判断 key 在 map 中,千万别用 in keys())
相关内容
- Python Appium 滑动、点击等操作,pythonappium,Python App
- mac配置python自然语言处理环境,python自然语言处理,Ⅰ、
- python 使用国内源安装软件,python国内,python lin
- python 二维数组键盘输入,python二维数组,1 m = int(
- Python 模块EasyGui,python模块easygui,1、msgBoxms
- error: <class 'xml.parsers.expat.ExpatError'&a
- python2.7和python3.6共存,使用pip安装第三方库,python2.7
- Python机器学习——Agglomerative层次聚类,,层次聚类(h
- ubuntu 16.04 python 3.x 安装OpenSSL,16.04openssl,错误提示:C
- Python cx_Oracle问题处理,pythoncx_oracle,今天第一次使用P
评论关闭