利用Python爬取豆瓣电影,python爬豆瓣电影,目标:使用Pytho
利用Python爬取豆瓣电影,python爬豆瓣电影,目标:使用Pytho
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中
我们先来看一下通过浏览器的方式来筛选某些特定的电影:
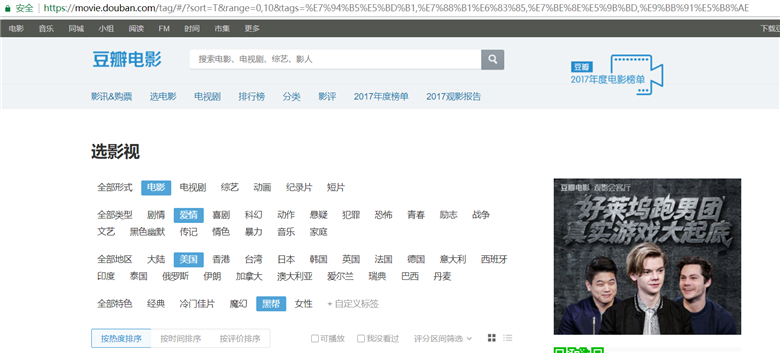
我们把URL来复制出来分析分析:
https://movie.douban.com/tag/#/?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD,%E9%BB%91%E5%B8%AE
有3个字段是非常重要的:
1.sort=T
2.range=0,10
3.tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD,%E9%BB%91%E5%B8%AE
我们一个一个的分析:
1.sort,顾名思义:应该是一种排序方式,那我们就去浏览器上看看点击哪里去改变他的值!
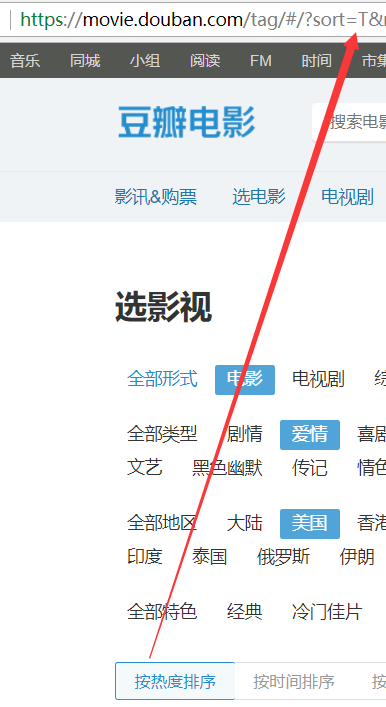
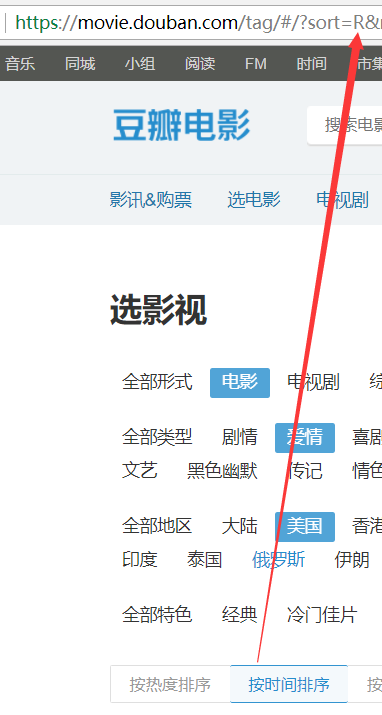
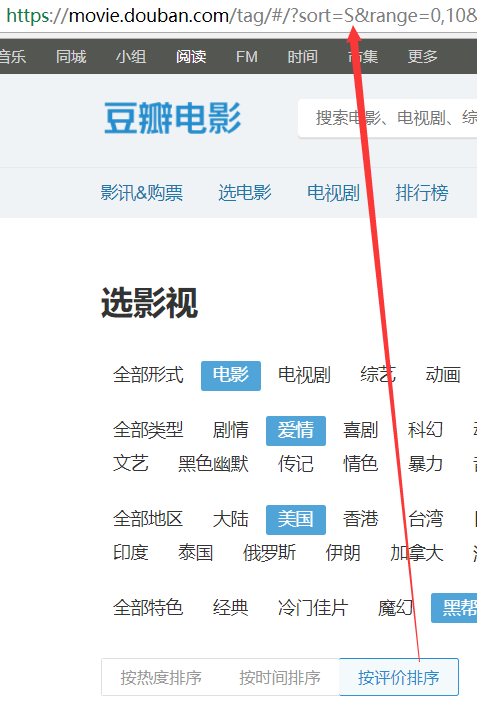
===>通过这三张截图我们就知道了有3中排序方式,这个查询参数就搞定了!
热度排序:T,时间排序:R,评价排序:S
2.range=0,10;同样的原理,这表示一个范围,区间,那我们再到浏览器上看看,哪里可以设置区间?
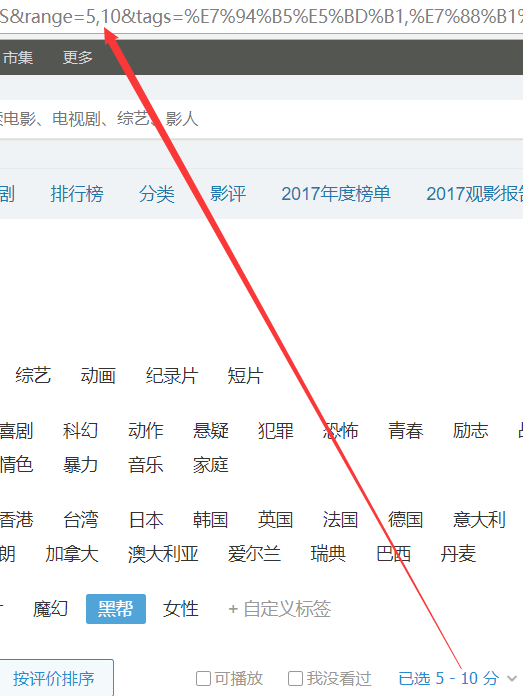
===>range参数我们也搞定了,它就是表示评分区间!
默认评分区间是:0-10
3.tags:同样的原理,我们来分析这个参数!
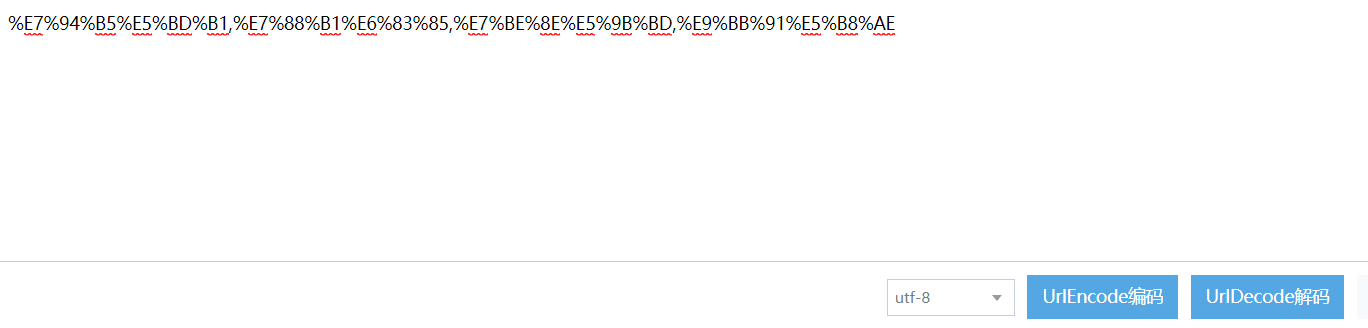
在第一张截图中我们选中了:电影,爱情,美国,黑帮4个标签,但是在tags里面我们看到的不是这写汉字,而是被编码过的形式!
那我怎么知道这些看起来乱七八糟的东西
(%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD,%E9%BB%91%E5%B8%AE)
就是由这4些参数(电影,爱情,美国,黑帮)编码的呢?
我们可以到网上进行解码看看正不正确?
编码格式:
解码格式:
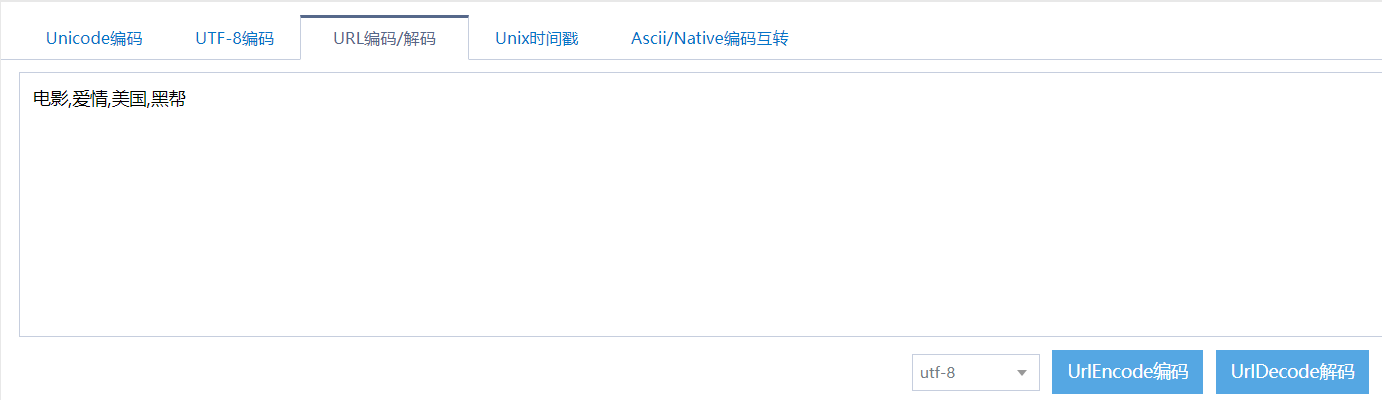
===>这样子我们也把tags参数解决了!
那么还有没有可以选择的参数呢?
细心的读者可能早就看到了,我们还有2个参数可以选择!
playbale=1:表示可播放
unwatched=1:表示还没看过的
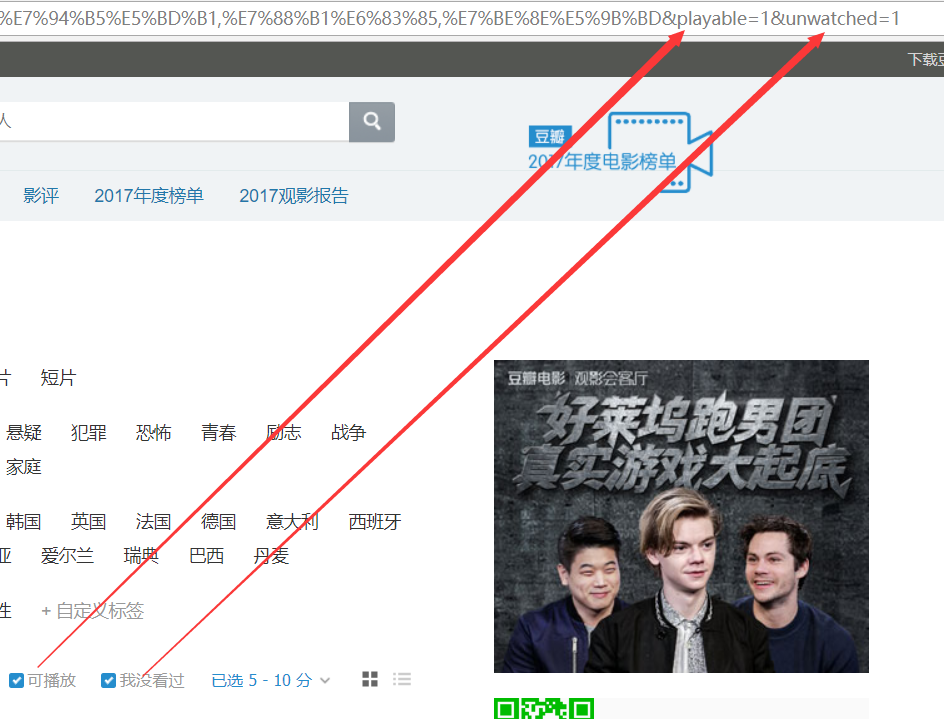
至此,我们就已经把URL中的查询参数全都弄明白了!
但是,又有一个问题了,当我们在浏览器中点击"加载更多"按钮时,这个URL并没有发生变化,但是出来的电影信息却加载出来了!这是为什么?
如果知道AJAX加载技术的读者可能知道这个原理,实际上就是异步加载,服务器不需要刷新整个网页,只需要刷新局部网页就可以把数据展示到网页中,这样不仅可以加快速度,也可以提到效率!
那么知道这个原理后,我们就可以利用Chrome进行抓包了!!!
重点来了:
抓包结果:
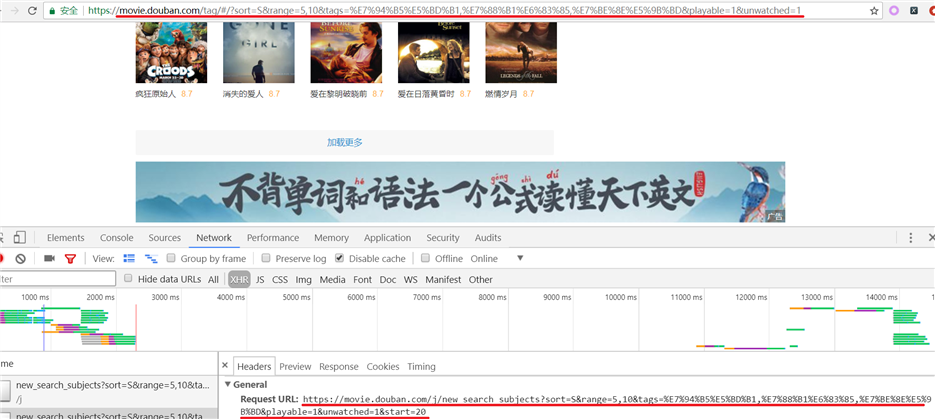
看看浏览器地址栏的URL与Request URL有什么不一样的地方?
我们在浏览器地址栏中看到的URL是:
https://movie.douban.com/tag/#/?
sort=S&range=5,10&tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD&playable=1&unwatched=1
实际浏览器发送的Request URL是:
https://movie.douban.com/j/new_search_subjects?
sort=S&range=5,10&tags=%E7%94%B5%E5%BD%B1,%E7%88%B1%E6%83%85,%E7%BE%8E%E5%9B%BD&playable=1&unwatched=1&start=0
除了被红色标记的地方不同之外,其他地方都是一样的!那我们发送请求的时候应该是用哪一个URL呢?
在上面我就已提到了,在豆瓣电影中,是采用异步加载的方式来加载数据的,也就是说在加载数据的过程中,地址栏中的URL是一直保持不变的,那我们还能用这个URL来发送请求吗?当然不能了!
既然不能用地址栏中的URL来发送请求,那我们就来分析一下浏览器实际发送的Request URL:
我们把这个URL复制到浏览器中看看会发生什么情况!

我们可以看到这个URL的响应结果恰恰就是我们想要的数据,而且根本不需要我们使用re,bs4,xpath等解析数据的工具来提取我们想要的数据,因为这种数据的格式刚好就是json格式,在Python中,我们可以利用一些工具把它转换成字典格式,来提取我们想要的数据.
距离我们成功还有一小步:
在这个URL中,我们看到还有一个参数:start,这个是干嘛的呢?
这个数值是一个偏移量,来控制每一次加载的偏移位置是在哪里!比如我们把它设置成20,那么得到的结果如下:

到这里,该案例的思路,难点就已经全都捋清楚了,剩下的就是代码的事情了!\(>0<)/ 加油
项目结构:
完整的代码如下:
settings.py
1 import random 2 3 4 User_Agent =[ 5 ‘Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50‘, 6 ‘Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50‘, 7 ‘Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0‘, 8 ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1‘, 9 ‘Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11‘,10 ‘Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11‘,11 ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11‘,12 ]13 14 # 设置UA15 headers = {‘User-Agent‘: random.choice(User_Agent)}mongoHelper.py
1 import pymongo 2 3 4 class MongoHelper: 5 """数据库操作""" 6 7 def __init__(self, collection_name=None): 8 # 启动mongo 9 self._client = pymongo.MongoClient(‘localhost‘, 27017)10 # 使用test数据库11 self._test = self._client[‘test‘]12 # 创建指定的集合13 self._name = self._test[collection_name]14 15 def insert_item(self, item):16 """插入数据"""17 #print(‘正在插入数据....‘)18 self._name.insert_one(item)19 20 def find_item(self):21 """查询数据"""22 data = self._name.find()23 return data24 25 26 def main():27 mongo = MongoHelper(‘collection‘)28 mongo.insert_item({‘a‘: 1})29 30 31 if __name__ == ‘__main__‘:32 main()douban.py
1 """ 2 爬取豆瓣电影的一些信息并保存到MongoDB数据库中 3 """ 4 5 import requests 6 from settings import headers 7 import string 8 from urllib import parse 9 from mongoHelper import MongoHelper 10 import time 11 from collections import deque 12 13 14 class DouBanMovieSpider: 15 16 def __init__(self): 17 self.session = requests.Session() 18 self.headers = headers 19 self.db = MongoHelper(‘DouBanMovies‘) 20 21 def split_condition(self): 22 """ 23 功能:与用户交互,指导用户输入筛选条件, 24 :return:返回已经去除了无效字符的查询参数 25 """ 26 27 print(‘以下这些tag你都可以不用输入,直接按Enter键,表示默认!‘) 28 from_tag = input(‘请输入你想看的影视形式(电影|电视剧|综艺...):‘) 29 type_tag = input(‘请输入你想看的影视类型(剧情|爱情|喜剧|科幻...):‘) 30 area_tag = input(‘请输入你想看的影视地区(大陆|美国|香港...):‘) 31 style_tag = input(‘请输入你想看的影视特色(经典|冷门佳片|黑帮...):‘) 32 33 34 range = input(‘请输入评分范围[0-10]:‘) 35 # 如果用户没有输入,那么默认就是:0,10 36 if not range: 37 range = 0,10 38 # 如果输入的小写的字符,那么就把它变成大写的 39 sort = input(‘请输入排序顺序(热度:T, 时间:R, 评价:S),三选一:‘).upper() 40 # 按照默认排序顺序(热度) 41 if not sort: 42 sort = ‘T‘ 43 playable = input(‘请选择是否可播放(不输入表示不可播放):‘) 44 # 如果用户如何任意字符,那么表示只查询可以播放的影视 45 if not playable: 46 playable = ‘1‘ 47 unwatched = input(‘请选择是否为我没看过(不输入表示我没看过):‘) 48 # 如果用户输入任意字符,就表示我已经看过了 49 if not unwatched: 50 unwatched = ‘‘ 51 query_param = { 52 ‘sort‘:sort, 53 ‘range‘:range, 54 ‘tags‘:[from_tag, type_tag, area_tag, style_tag], 55 ‘playable‘:playable, 56 ‘unwatched‘:unwatched, 57 } 58 # string.printable:表示ASCII字符就不用编码了 59 query_url = parse.urlencode(query_param,safe=string.printable) 60 # 去除查询参数中无效的字符 61 invalid_chars = [‘(‘, ‘)‘, ‘[‘, ‘]‘, ‘+‘, ‘\‘‘] 62 for char in invalid_chars: 63 if char in query_url: 64 query_url = query_url.replace(char, ‘‘) 65 # 把干净的查询参数返回出去 66 return query_url 67 68 def download_movies(self, url): 69 """ 70 功能:下载已过滤后的影视 71 :param url: 过滤后的影视地址 72 :return: 返回真正的影视地址 73 """ 74 if not url: 75 print(‘download_movies() error: url是None‘) 76 return 77 78 resp = self.session.get(url, headers=self.headers) 79 if resp.status_code == 200: 80 print(‘download_movies():下载成功!‘) 81 # 获取响应文件中的电影数据 82 movies = dict(resp.json()).get(‘data‘) 83 if movies: 84 return True, movies 85 # 响应结果中没有电影了! 86 else: 87 print(‘download_movies() error!已经没有请求到电影数据了!!‘) 88 else: 89 print(‘download_movies() error! status_code:{}, url:{}‘ 90 .format(resp.status_code, resp.url)) 91 92 return False, None 93 94 95 def save_movies(self, movies, id): 96 """ 97 功能:把请求到的电影保存到数据库中 98 :param data: 电影集合 99 :return:100 """101 if not movies:102 print(‘save_movies() error: moives为None!!!‘)103 return104 105 print(‘save_movies():正在保存电影到数据库中...‘)106 107 # 初始时,数据库中还没有数据,就直接插入就好了!108 if id == 0:109 for movie in movies:110 id += 1111 movie[‘_id‘] = id112 self.db.insert_item(movie)113 else:114 # 当数据库中有数据时我才进行查询操作115 all_movies = self.find_movies()116 # 用来保存已经存在数据库中的电影的title117 titles = []118 for existed_movie in all_movies:119 # 把已经在数据库中的电影的title提取出来120 titles.append(existed_movie.get(‘title‘))121 122 for movie in movies:123 # 通过标题来判断带插入的数据是否已存在数据库中124 if movie.get(‘title‘) not in titles:125 id += 1126 movie[‘_id‘] = id127 self.db.insert_item(movie)128 else:129 print(‘save_movies():该电影"{}"已经在数据库了!!!‘.format(movie.get(‘title‘)))130 131 def find_movies(self):132 """133 功能:查询数据库中所有的电影数目134 :return: 返回所有的电影数目135 """136 all_movies = deque()137 data = self.db.find_item()138 for item in data:139 all_movies.append(item)140 return all_movies141 142 def main():143 base_url = ‘https://movie.douban.com/j/new_search_subjects?‘144 douban = DouBanMovieSpider()145 query_param = douban.split_condition()146 start = 0147 # 把id设为数据库中最后一个,避免冲突148 id = len(douban.find_movies()) #149 while True :150 full_url = base_url + query_param + ‘&start={}‘.format(str(start))151 # print(‘full_url:‘,full_url)152 enable, movies= douban.download_movies(full_url)153 # 当HTTP响应返回电影数据,那么把他们保存到数据库中154 if enable:155 douban.save_movies(movies,id)156 else:157 print(‘main():所有电影都已保存成功!共保存了{}条电影信息!!!!‘.format(start))158 print(‘main():数据库中有{}部电影信息!!‘.format(len(douban.find_movies())))159 return160 # 睡眠2s,让访问起来更加人性化161 time.sleep(2)162 # 设置每次获取电影的数据都是以20为偏移量163 start += 20164 # id是用来设置数据库中的每条数据的‘_id‘字段,增长步长必须与start一致165 id += 20166 167 if __name__ == ‘__main__‘:168 main()小结:在本次案例中,主要的难点有:查询参数的组合那部分和了解异步加载的原理从而找到真正的URL!查询参数的设置主要用到urlencode()方法,当我们不要把ASCII字符编码的时候,我们要设置safe参数为string.printable,这样只要把一些非ASCII字符编码就好了,同样quote()也是用来编码的,也有safe参数;那么本例中为什么要使用urlencode()方法呢?主要是通过观察URL是key=value的形式,所以才选用它!当我们把数据插入到数据库中时,如果是有相同的名字的电影,我们就不插入,这样也是处于对性能的考虑,合理利用资源!
利用Python爬取豆瓣电影
相关内容
- Python3 Tkinter基础 Frame bind 绑定鼠标左右键 打印点击的位
- python练习题,,python基础练习
- Python:GUI之tkinter学习笔记3事件绑定,pythontkinter,相关内
- Python文章相关性分析---金庸武侠小说分析,,最近常听同
- Python全栈之路--Django ORM详解,--djangoorm,ORM:(在djan
- Python中使用面状矢量裁剪栅格影像,并依据Value值更改
- 【Python3爬虫】有道翻译,python3爬虫有道,准备:Python
- 学习 python 编写规范 pep8 的问题笔记,pythonpep8,决定开始
- Python自动化开发学习12-MariaDB,python12-mariadb,关系型数据
- python实战===如何优雅的打飞机,python实战打飞机,这是一
评论关闭