从电商页面埋点说起,,背景互联网发展到现在
从电商页面埋点说起,,背景互联网发展到现在
背景
互联网发展到现在,数据的重要性已经不需要再多的强调,那如何做好数据搜集的工作则是每一家公司都要面临的问题。尤其是像天猫、京东、寺库这样的电商公司,数据的统计可以提升用户购买的用户体验,可以方便运营和产品调整销售策略等等。可见页面埋点多么重要。今天就让我们从无到有制作一个埋点上报工具。
主要内容:
什么是埋点埋点原理埋点的种类电商页面前端埋点规范封装一个异步请求IntersectionObserver -新一代元素观察接口基于VUE从零开始封装一个前端数据埋点工具后端日志格式(前端理解即可)后端nginx配置(前端理解即可)需要改进的地方 image
image什么是埋点
所谓“埋点”,是数据采集领域(尤其是用户行为数据采集领域)的术语,指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。比如用户某个icon点击次数、观看某个视频的时长等等。
埋点原理分析和流程概述
简单来说,网站统计分析工具需要收集到用户浏览目标网站的行为(如打开某网页、点击某按钮、将商品加入购物车等)及行为附加数据(如某下单行为产生的订单金额等)。早期的网站统计往往只收集一种用户行为:页面的打开。而后用户在页面中的行为均无法收集。这种收集策略能满足基本的流量分析、来源分析、内容分析及访客属性等常用分析视角,但是,随着ajax技术的广泛使用及电子商务网站对于电子商务目标的统计分析的需求越来越强烈,这种传统的收集策略已经显得力不能及。
后来,Google在其产品谷歌分析中创新性的引入了可定制的数据收集脚本,用户通过谷歌分析定义好的可扩展接口,只需编写少量的javascript代码就可以实现自定义事件和自定义指标的跟踪和分析。目前百度统计、搜狗分析等产品均照搬了谷歌分析的模式。
其实说起来两种数据收集模式的基本原理和流程是一致的,只是后一种通过javascript收集到了更多的信息。下面看一下现在各种网站统计工具的数据收集基本原理。
 20170929153435397.png
20170929153435397.png首先,用户的行为会---这里姑且先认为行为就是打开网页。当网页被打开,页面中的埋点javascript片段会被执行,一般网站统计工具都会要求用户在网页中加入一小段javascript代码,这个代码片段一般会动态创建一个script标签,并将src指向一个单独的js文件,例子中为dot.js.此时这个单独的js文件(图中绿色节点)会被浏览器请求到并执行,这个js往往就是真正的数据收集脚本。数据收集完成后,js会请求一个后端的数据收集脚本(图中的backend),这个脚本一般是一个伪装成图片的动态脚本程序,可能由php、python或其它服务端语言编写,js会将收集到的数据通过http参数的方式传递给后端脚本,后端脚本解析参数并按固定格式记录到访问日志。
上面是一个数据收集的大概流程,下面以寺库商城为例,对每一个阶段进行一个相对详细的分析。
1.1 埋点脚本执行阶段
技术栈为vue,当页面中的资源加载完成后,执行埋点的脚本,如下图
 image.png
image.png1.2 数据收集脚本执行阶段
数据收集脚本(dot.js)被请求后当页面展示会被执行,这个脚本一般要做如下几件事:
(1)通过浏览器内置javascript对象收集页面基本信息,如页面title(通过document.title)、url(页面链接)、用户显示器分辨率(通过windows.screen)、cookie信息(通过document.cookie)等等一些信息。
(2)收集曝光楼层信息。
(3)将上面两步收集的数据进行拼接。
(4)请求一个后端脚本,将信息放在http request参数中携带给后端脚本。
这里唯一的问题是步骤4,javascript请求后端脚本常用的方法是ajax,但是ajax是不能跨域请求的。这里dot.js在被统计网站的域内执行,而后端脚本在另外的域,ajax行不通。一种通用的方法是js脚本创建一个Image对象(log.gif),将Image对象的src属性指向后端脚本并携带参数,此时即实现了跨域请求后端。这也是后端脚本为什么通常伪装成gif文件的原因。通过http抓包可以看到dot.js对log.gif的请求:
 image.png
image.png1.3 后端脚本执行阶段
log.gif是一个伪装成gif的脚本。这种后端脚本一般要完成以下几件事情:
(1)解析http请求参数的到信息。
(2)从服务器(WebServer)中获取一些客户端无法获取的信息,如访客ip等。
(3)将信息按格式写入log。
(4)生成一副1×1的空gif图片作为响应内容并将响应头的Content-type设为image/gif。
(5)在响应头中通过Set-cookie设置一些需要的cookie信息。
之所以要设置cookie是因为如果要跟踪唯一访客,通常做法是如果在请求时发现客户端没有指定的跟踪cookie,则根据规则生成一个全局唯一的cookie并种植给用户,否则Set-cookie中放置获取到的跟踪cookie以保持同一用户cookie不变(见图4)。
埋点的种类
业界的埋点方案主要分为以下三类:
代码埋点
代码埋点就是在需要数据统计的地方植入数据上报的代码,统计用户行为。
优点:可以非常精确的选择什么时候发送数据。
缺点:维护代价较大,每一次更新都要对埋点代码进行维护,否则大概率搜集不到旧版本的数据。
可视化埋点
利用可视化交互手段,数据产品/数据分析师可以通过可视化界面(管理后台连接设备) 配置事件,如下是腾讯移动分析的可视化埋点界面。可视化埋点仍需要先配置相关事件,再采集。
 从数据产品经理视角,聊聊埋点的意义
从数据产品经理视角,聊聊埋点的意义 从数据产品经理视角,聊聊埋点的意义优点:埋点只需业务同学接入,无需开发支持;缺点:仅支持客户端行为。
从数据产品经理视角,聊聊埋点的意义优点:埋点只需业务同学接入,无需开发支持;缺点:仅支持客户端行为。无埋点
无埋点是指开发人员集成采集 SDK 后,SDK 便直接开始捕捉和监测用户在应用里的所有行为,并全部上报,不需要开发人员添加额外代码。
数据分析师/数据产品 通过管理后台的圈选功能来选出自己关注的用户行为,并给出事件命名。之后就可以结合时间属性、用户属性、事件进行分析了。所以无埋点并不是真的不用埋点了。
优点:
无需开发,业务人员埋点即可;
支持先上报数据,后进行埋点。
缺点:
数据量大;
仅仅支持客户端。
无埋点和可视化埋点均不需要开发支持,仅数据业务同学进行设置即可。但两者数据上报-埋点设置存在加大的差异:无埋点支持在数据上报之后再进行埋点设置,因而数据采集/上报的量远大于可视化埋点。
因而无埋点的数据大都有清空机制,例如growingIO,允许版本发布后7天内设置埋点,超过7天数据清空,无法追溯。
这次主要讲代码埋点
代码埋点分为 命令式埋点 与 声明式埋点 :
命令式埋点,顾名思义,开发者需要手动在需要埋点的节点处进行埋点。如点击按钮或链接后的回调函数、页面ready时进行请求的发送。大家肯定都很熟悉这样的代码:
// 页面加载时发送埋点请求$(document).ready(function(){ // ... 这里存在一些业务逻辑 sendRequest(params);});// 按钮点击时发送埋点请求$(‘button‘).click(function(){ // ... 这里存在一些业务逻辑 sendRequest(params);});可以很容易发现,这样的做法很有可能会将埋点代码侵入业务代码,这使整体业务代码变得繁琐,容易出错,且后续代码会愈加膨胀,难以维护。所以,我们需要让埋点的代码与具体的业务逻辑解耦,即 声明式埋点 ,从而提高埋点的效率和代码的可维护性。
声明式埋点理论上,只需要关注两个问题:
需要埋点的DOM节点;所需携带的数据因此,可以很快想出一个声明式埋点的方法:
// key表示埋点的唯一标识;act表示埋点方式<span v-clstag-dot = "{‘act‘:‘thumbs‘, ‘key‘: ‘details_product_1_dot_thumbs‘, ‘productId‘: product.productId}">点赞</span>稍后会详细讲声明式埋点的实现原理
电商页面前端埋点规范
建立一个好的规范非常重要,包括命名规范、上报规范、数据规范和使用规范*。
1.埋点命名规范
埋点名称为上报日志中的key字段,第三条会讲到,我们当前的做法是埋点名称只能是由字母、数字、下划线组成,并保证在应用内唯一。
常用规则的举例如下:
比如行为埋点:{页面名称}+{组件名称}+{组件id}+{功能}+{动作}
组件名称和动作最为重要,它决定着后端收到埋点后要进行哪种操作,开发过程中要和后端严格制定好名称,比如点击的是商品列表。我们约定好了商品为product,那么组件名称就必须为product.比如点击了收藏,和后端约定好的是thumbs,动作就必须为:thumbs。另外,id从0开始。
组件名称列表:
广告:ad
商品:product
购物车:car
其他:可和后端协商
动作列表:
点击:click
收藏:collection
评论:comment
点赞; thumbs
加入购物车: add
其他:可和后端协商
示例:
// key表示埋点的唯一标识;act表示埋点方式<span v-clstag-dot = "{‘act‘:‘thumbs‘, ‘key‘: ‘details_product_1_dot_thumbs‘, ‘productId‘: product.productId}">点赞</span>埋点启动日志和错误上报日志:{页面名称}+{页面id}+{动作}
示例:
‘key‘: ‘details_123_show‘
‘key‘:‘details_123_error‘
2.埋点上报规范
(1)针对曝光埋点数据的上报策略一般如下:
基于时间间隔:每隔 n秒(时间间隔可以根据公司的业务情况自定义)
基于数据条数:每累积 n条数据(条数可以自定义)
不间断实时上报,如果是低频率,数据量小,实时性要求高的数据可以不设限制
为以防用户卸载 App或者关闭浏览器造成本地数据的丢失,会将未上报的埋点存储在localstorage,浏览器关闭埋点数据并不会被删除,如果用户再次访问,会启动上报。基于Native提供的bridge,让Native帮忙持久化数据,并在再次进入时,启动上报。这里也可以创建一个单独的串行队列,来实现对本地持久化数据的逐个上报。
(2)事件埋点和错误埋点的上报策略
事件发生后及时上报数据规范
每个公司都有自己的埋点数据规范,里面汇总了需要上报的埋点数据,例如
 image.png
image.png 电商前端数据埋点.png使用规范
电商前端数据埋点.png使用规范(1)引入埋点脚本一定要在页面资源加载完,例如:
import { dot } from ‘./assets/js/dot‘// 中央事件总线封装Vue.use(VueBus)Vue.config.productionTip = false/* eslint-disable no-new */// Vue.directive() 这个方法写在new Vue之前dot.clickExpDot(Vue)window.onload = function () { dot.postError() dot.dotPageReadyData() dot.show()}new Vue({ el: ‘#app‘, router, store, // 使用store components: { App }, template: ‘<App/>‘})
(2)声明式埋点在html中引入的规范,例如:
#曝光埋点的用法<div class="exposure-statistics" show-dot="{‘act‘:‘show‘,‘ key‘:‘details_ad_1_flowtab_show‘}">
#事件埋点的用法<span v-clstag-dot = "{‘act‘:‘thumbs‘, ‘key‘: ‘details_product_1_dot_thumbs‘, ‘productId‘: product.productId}">点赞</span>
封装一个异步请求
1. axios(考虑到跨域问题,本次没有使用)
在vue项目中,和后台交互获取数据这块,我们通常使用的是axios库,它是基于promise的http库,可运行在浏览器端和node.js中。他有很多优秀的特性,例如拦截请求和响应、取消请求、转换json、客户端防御cSRF等。所以我们的尤大大也是果断放弃了对其官方库vue-resource的维护,直接推荐我们使用axios库。如果还对axios不了解的,可以移步axios文档。
安装
npm install axios; // 安装axios复制代码引入
一般我会在项目的src目录中,新建一个request文件夹,然后在里面新建一个http.js和一个api.js文件。http.js文件用来封装我们的axios,api.js用来统一管理我们的接口。
代码如下:
import axios from ‘axios‘// import QS from ‘qs‘import { Toast } from ‘vant‘// 环境的切换if (process.env.NODE_ENV === ‘development‘) { axios.defaults.baseURL = ‘http://localhost:8080‘} else if (process.env.NODE_ENV === ‘production‘) { axios.defaults.baseURL = ‘http://localhost:8080‘}// 请求超时时间axios.defaults.timeout = 10000// post请求头axios.defaults.headers.post[‘Content-Type‘] = ‘application/x-www-form-urlencoded;charset=UTF-8‘// 请求拦截器axios.interceptors.request.use(config => { // 请求处理 return config}, err => { // 处理请求错误 return Promise.reject(err)})// 响应拦截器axios.interceptors.response.use( response => { if (response.status === 200) { return Promise.resolve(response.data) } else { return Promise.reject(response) } }, // 服务器状态码不是200的情况 error => { if (error.response.status) { switch (error.response.status) { case 500: Toast({ message: ‘系统错误‘, duration: 1000, forbidClick: true }) break case 201: Toast({ message: ‘业务失败!‘, duration: 1000, forbidClick: true }) break // 其他错误,直接抛出错误提示 default: Toast({ message: ‘失败‘, duration: 1500, forbidClick: true }) } return Promise.reject(error.response) } })/** * get方法,对应get请求 * @param {String} url [请求的url地址] * @param {Object} params [请求时携带的参数] */export function get (url, params) { return new Promise((resolve, reject) => { axios.get(url, { params: params }).then(res => { resolve(res) }).catch(err => { reject(err.data) }) })}/** * post方法,对应post请求 * @param {String} url [请求的url地址] * @param {Object} params [请求时携带的参数] */export function post (url, params) { return new Promise((resolve, reject) => { // axios.post(url, QS.stringify(params)).then(res => { axios.post(url, params).then(res => { resolve(res) }).catch(err => { reject(err.data) }) })}使用方式
const getGroupId = params => post(commonApi.apiGetGroupId, params)2. 用img发送请求
用img发送请求的方法英文术语叫:image beacon
主要应用于只需要向服务器发送日志数据的场合,且无需服务器有消息体回应。比如收集访问者的统计信息。
这样做和ajax请求的区别在于:
1.只能是get请求,因此可发送的数据量有限。
2.只关心数据是否发送到服务器,服务器不需要做出消息体响应。并且一般客户端也不需要做出响应。
3.实现了跨域
使用图片上报埋点是当下比较流行的一种方式,阿里,京东都在用。简单的封装如下:
// pageview是将上报的json格式的数据转换成a=b&c=d格式的字符串export default function analytics (action = ‘pageview‘) { (new Image()).src = `https://xxx/test_upload?action=${action}×tamp=${Date.now()}`}IntersectionObserver,新一代元素观察接口
统计页面区域曝光,需要判断区域是否在视口中,这个时候就需要用到IntersectionObserver了。
概念
IntersectionObserver接口(从属于Intersection Observer API)为开发者提供了一种可以异步监听目标元素与其祖先或视窗(viewport)交叉状态的手段。祖先元素与视窗(viewport)被称为根(root)。
重点看这里监听目标元素与其祖先或视窗交叉状态的手段,其实就是观察一个元素是否在视窗可见。
 image
image可以看到,交叉了就是说明当前元素在视窗里,当前就是可见的了。
API
var observer = new IntersectionObserver(callback, options)其实就是一个简单的构造函数。
以上代码会返回一个IntersectionObserver实例,callback是当元素的可见性变化时候的回调函数,options是一些配置项(可选)。
我们使用返回的这个实例来进行一些操作。
Observer.observe(document.querySelector(‘img‘)) 开始观察,接受一个DOM节点对象Observer.unobserve(element) 停止观察 接受一个element元素Observer.disconnect() 关闭观察器options
root
用于观察的根元素,默认是浏览器的视口,也可以指定具体元素,指定元素的时候用于观察的元素必须是指定元素的子元素
threshold
用来指定交叉比例,决定什么时候触发回调函数,是一个数组,默认是[0]。
const options = { root: null, threshold: [0, 0.5, 1]}var Observer = new IntersectionObserver(callback, options)Observer.observe(document.querySelector(‘img‘))上面代码,我们指定了交叉比例为0,0.5,1,当观察元素img0%、50%、100%时候就会触发回调函数
rootMargin
用来扩大或者缩小视窗的的大小,使用css的定义方法,10px 10px 30px 20px表示top、right、bottom 和 left的值
const options = { root: document.querySelector(‘.box‘), threshold: [0, 0.5, 1], rootMargin: ‘30px 100px 20px‘}为了方便理解,我画了张图,如下
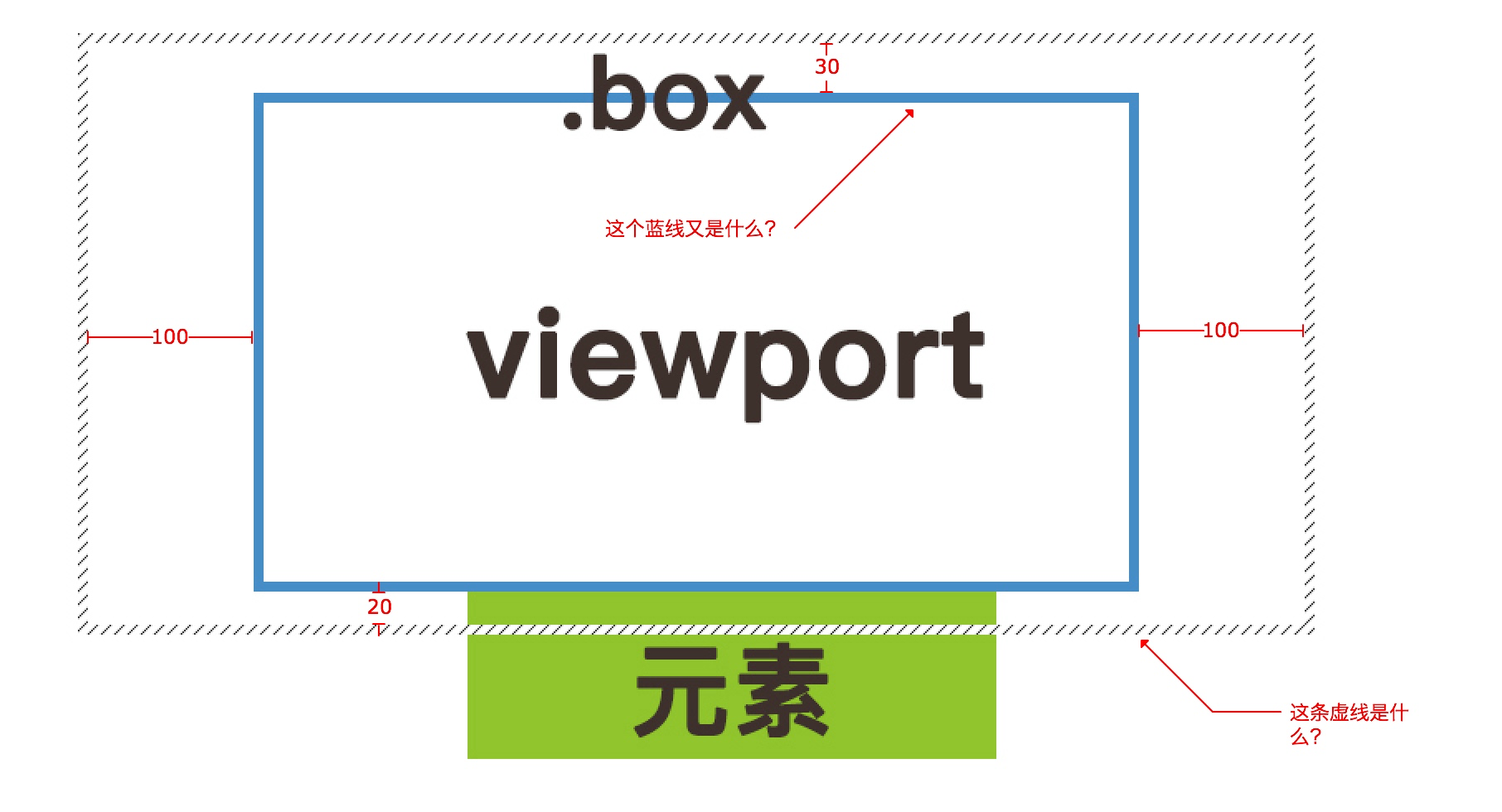
首先我们来看下图上的问题,蓝线是什么呢?他就是咱们定义的root元素,我们添加了rootMargin属性,将视窗的增大了,虚线就是现在的视窗,所以元素现在也就在视窗里面了。
由此可见,root元素只有在rootMargin为空的时候才是绝对的视窗。
说了简单的options,接下来我们看下callback。
callback
上面我们说到,当元素的可见性变化时,就会触发callback函数。
callback函数会触发两次,元素进入视窗(开始可见时)和元素离开视窗(开始不可见时)都会触发
var io = new IntersectionObserver((entries)=>{ console.log(entries)})io.observe($0)以上代码,请在chrome控制台进行调试,这里我使用了$0选择了上一次我审查元素的选择的节点
运行结果如下
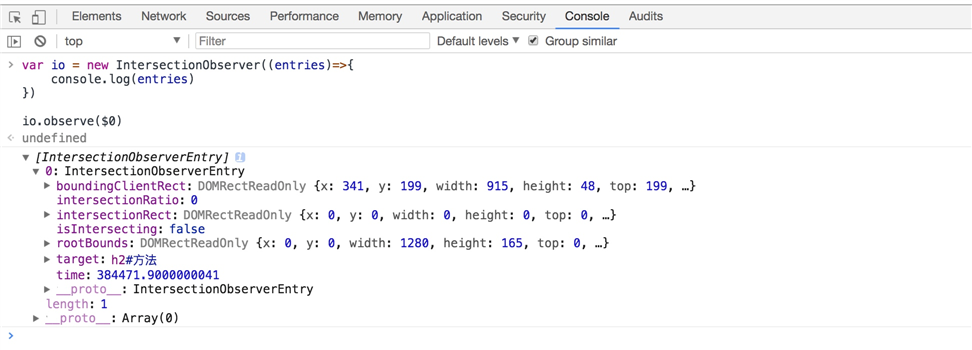 image
image我们可以看到callback函数有个entries参数,它是个IntersectionObserverEntry对象数组,接下来我们重点说下IntersectionObserverEntry对象
IntersectionObserverEntry
IntersectionObserverEntry提供观察元素的信息,有七个属性。
boundingClientRect 目标元素的矩形信息
intersectionRatio 相交区域和目标元素的比例值 intersectionRect/boundingClientRect 不可见时小于等于0
intersectionRect 目标元素和视窗(根)相交的矩形信息 可以称为相交区域
isIntersecting 目标元素当前是否可见 Boolean值 可见为true
rootBounds 根元素的矩形信息,没有指定根元素就是当前视窗的矩形信息
target 观察的目标元素
time 返回一个记录从IntersectionObserver的时间到交叉被触发的时间的时间戳
上面几个矩形信息的关系如下
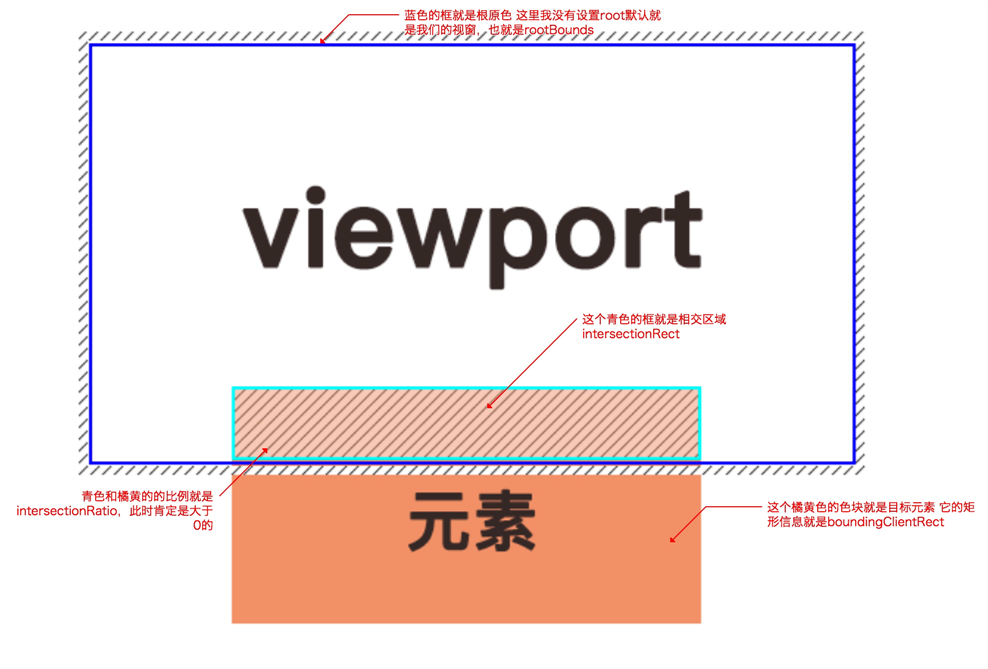
?? 划重点
intersectionRatio和isIntersecting是用来判断元素是否可见的
使用IntersectionObserver编写图片懒加载
好了,通过上面一些概念我们大概了解了IntersectionObserver是个什么东西,接下来我们用它来写点代码,写什么呢?没错就是懒加载。
通过IntersectionObserver来实现懒加载,就简单的多了,我们只需要设置回调,判断当前元素是否可见,再进行渲染操作就行了,而不用去关心内部的计算。
主要代码如下
const io = new IntersectionObserver(()=>{ // 实例化 默认基于当前视窗}) let ings = document.querySelectorAll(‘[data-src]‘) // 将图片的真实url设置为data-src src属性为占位图 元素可见时候替换srcfunction callback(entries){ entries.forEach((item) => { // 遍历entries数组 if(item.isIntersecting){ // 当前元素可见 item.target.src = item.target.dataset.src // 替换src io.unobserve(item.target) // 停止观察当前元素 避免不可见时候再次调用callback函数 } })}imgs.forEach((item)=>{ // io.observe接受一个DOM元素,添加多个监听 使用forEach io.observe(item)})基于VUE从零开始封装一个前端数据埋点工具
到此。所有编写埋点的准备知识就差不多了,接着用vue-cli创建一个vue项目。项目目录结构简化如下:
|-- build // 项目构建(webpack)相关代码| |-- build.js // 生产环境构建代码| |-- check-version.js // 检查node、npm等版本| |-- webpack.base.conf.js // webpack基础配置| |-- webpack.dev.conf.js // webpack开发环境配置| |-- webpack.prod.conf.js // webpack生产环境配置|-- config // 项目开发环境配置| |-- dev.env.js // 开发环境变量| |-- index.js // 项目一些配置变量| |-- prod.env.js // 生产环境变量| |-- test.env.js // 测试环境变量|-- mySql // 使用node开发的接口,这次没有使用| |-- api.js // node开发的api| |-- db.js // 数据库连接配置| |-- index.js // node开启的服务| |-- router.js // api封装 | |-- sqlMap.js // api名称|-- src // 源码目录| |-- api // axios封装的接口请求| |-- components // vue公共组件| |-- page // vue页面| | |--dot.vue //用来展示埋点上报的详情页| |-- assets // 公共资源| | |--js //公共脚本| | | |--dot.js //封装的前端数据埋点工具| |-- App.vue // 页面入口文件| |-- main.js // 程序入口文件,加载各种公共组件|-- static // 静态文件,比如一些图片,json数据等| |-- data // 群聊分析得到的数据用于数据可视化|-- .babelrc // ES6语法编译配置|-- .editorconfig // 定义代码格式|-- .gitignore // git上传需要忽略的文件格式|-- README.md // 项目说明|-- favicon.ico |-- index.html // 入口页面|-- package.json // 项目基本信息基于Vue指令的声明式埋点
由于在埋点的需求中使用了Vue作为基础框架,结合上面声明式埋点的例子,很容易就联想到 Vue自定义指令。Vue自定义指令提供了一种机制,将数据的变化映射为 DOM 行为。以 Vue 1.x 版本为例,自定义指令提供了几个钩子函数:
bind:只调用一次,在指令第一次绑定到元素上时调用。
update: 在 bind 之后立即以初始值为参数第一次调用,之后每当绑定值变化时调用,参数为新值与旧值
unbind:只调用一次,在指令从元素上解绑时调用
这样的特性可以很好的解决以上的一些问题。我们只需要像这样:
Vue.directive(‘stat‘, { bind: function () { // 准备工作 }, update: function (newValue, oldValue) { // 值更新时的工作 // 也会以初始值为参数调用一次, 此时可以根据传值类型来进行相应埋点行为的请求处理 }, unbind: function () { // 清理工作 }})在一个Vue应用中,不需要再去遍历DOM树,因为在Vue应用中基本所有DOM操作都是使用数据的变更结合Vue的内置指令实现,Vue可以感知到这些变更。在指令从元素上解绑时我们也可以去销毁已经绑定的事件。
在这个项目中我们给点击,点赞,评论,收藏添加了声明式埋点,我们只需要像下面一样声明就可以了:
<div v-clstag-dot = "{‘act‘:‘click‘, ‘key‘: product.productId}"></div>给vue添加内置指令的代码:
/** * @description: 点击统计埋点(命令式)) * @param {obj} vue实例 */ clickExpDot: function (Vue) { let that = this Vue.directive(‘clstag-dot‘, { bind: function (el, binding, vnode) { el.addEventListener(‘click‘, (e) => { e.stopPropagation() let time = { timestamp: new Date().getTime() } let query = Object.assign({}, time, binding.value, that.params) that.analytics(that.splicingStr(query)) }, false) } }) }最后,需要在main.js中引入声明式埋点,错误监控,上报pv,uv,区域展示埋点等就可以了
// dot.clickExpDot() 这个方法写在new Vue之前import { dot } from ‘./assets/js/dot‘dot.clickExpDot(Vue)// 页面加载完成后执行错误监控,上报pv,uv,区域展示埋点等window.onload = function () { dot.postError() dot.dotPageReadyData() dot.show()}整个项目的完整源代码在github上埋点工具
后端日志格式(前端同学理解就好,可不用实现)
日志格式主要考虑日志分隔符,一般会有以下几种选择:固定数量的字符、制表符分隔符、空格分隔符、其他一个或多个字符、特定的开始和结束文本。
我们在 nginx 的配置文件中定义日志格式:
log_format"$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url||$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_agent||$u_account";注意这里以 u_开头的是我们待会会自己定义的变量,其它的是nginx内置变量
后端nginx配置(前端同学理解就好,可不用实现)
log.gif 是后端脚本,是一个伪装成 gif 图片的脚本。后端脚本一般需要完 成以下几件事情:
1、解析 http 请求参数得到信息。
2、从 Web 服务器中获取一些客户端无法获取的信息,如访客 ip 等。
3、将信息按格式写入 log。
4、生成一副 1×1 的空 gif 图片作为响应内容并将响应头的 Content-type设为 image/gif。
5、在响应头中通过 Set-cookie 设置一些需要的 cookie 信息。
之所以要设置 cookie 是因为如果要跟踪唯一访客,通常做法是如果在请求 时发现客户端没有指定的跟踪 cookie,则根据规则生成一个全局唯一的 cookie 并 种植给用户,否则 Set-cookie 中放置获取到的跟踪 cookie 以保持同一用户 cookie 不变。这种做法虽然不是完美的(例如用户清掉 cookie 或更换浏览器会被认为是两个用户),但是目前被广泛使用的手段。
我们使用 nginx 的 access_log 做日志收集,不过有个问题就是 nginx 配置本身的逻辑表达能力有限,所以选用 OpenResty 做这个事情。
番外:什么是OpenResty?
OpenResty是一个基于 Nginx 与 Lua 的高性能 Web 平台,其内部集成了大量精良的 Lua 库、第三方模块以及大多数的依赖项。其中的核心是通过 ngx_lua 模块集成了 Lua,从而在 nginx 配置文 件中可以通过 Lua 来表述业务。而Lua 是一种轻量小巧的脚本语言,用标准 C 语言编写并以源代码形式开放, 其设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
这里给出Nginx配置文件
worker_processes 2;events { worker_connections 1024;}http { include mime.types; default_type application/octet-stream; log_format main ‘$remote_addr - $remote_user [$time_local] "$request" ‘ ‘$status $body_bytes_sent "$http_referer" ‘ ‘"$http_user_agent" "$http_x_forwarded_for"‘; log_format user_log_format "$msec||$remote_addr||$status||$body_bytes_sent||$u_domain||$u_url||$u_title||$u_referrer||$u_sh||$u_sw||$u_cd||$u_lang||$http_user_agent||$u_account"; sendfile on; #允许sendfile方式传输文件,默认为off keepalive_timeout 65; #连接超时时间,默认为75s server { listen 80; server_name localhost; location /log.gif { #伪装成gif文件 default_type image/gif; #nginx本身记录的access_log,日志格式为main access_log logs/access.log main; access_by_lua " -- 用户跟踪cookie名为__utrace local uid = ngx.var.cookie___utrace if not uid then -- 如果没有则生成一个跟踪cookie,算法为md5(时间戳+IP+客户端信息) uid = ngx.md5(ngx.now() .. ngx.var.remote_addr .. ngx.var.http_user_agent) end ngx.header[‘Set-Cookie‘] = {‘__utrace=‘ .. uid .. ‘; path=/‘} if ngx.var.arg_domain then -- 通过subrequest到/i-log记录日志,将参数和用户跟踪cookie带过去 ngx.location.capture(‘/i-log?‘ .. ngx.var.args .. ‘&utrace=‘ .. uid) end "; #此请求资源本地不缓存 add_header Expires "Fri, 01 Jan 1980 00:00:00 GMT"; add_header Pragma "no-cache"; add_header Cache-Control "no-cache, max-age=0, must-revalidate"; #返回一个1×1的空gif图片 empty_gif; } location /i-log { #内部location,不允许外部直接访问 internal; #设置变量,注意需要unescape set_unescape_uri $u_domain $arg_domain; set_unescape_uri $u_url $arg_url; set_unescape_uri $u_title $arg_title; set_unescape_uri $u_referrer $arg_referrer; set_unescape_uri $u_sh $arg_sh; set_unescape_uri $u_sw $arg_sw; set_unescape_uri $u_cd $arg_cd; set_unescape_uri $u_lang $arg_lang; set_unescape_uri $u_account $arg_account; #打开subrequest(子请求)日志 log_subrequest on; #自定义采集的日志,记录数据到user_defined.log access_log logs/user_defined.log user_log_format; #输出空字符串 echo ‘‘; } }}整个项目的后端部署可参考:网站用户行为日志采集和后台日志服务器搭建 此处不做过多的解释,搭建教程网上有很多,可根据自己的实际情况部署。
 image.png打开network可以看到携带的参数
image.png打开network可以看到携带的参数 image.png
image.png为了方便观察,将生成的日志保存为txt文件,以日期加log.text的格式命名:
 image.png
image.png项目需要改进的地方
无网络延时上报
思考一个问题,假如我们的页面处于断网离线状态(比如就是信号不好),用户在这期间进行了操作,而我们又想收集这部分数据会怎样?
假如断网非常短暂,脚本持续执行并且未触发打包上传。由于log仍保留在内存中,继续执行直到触发可上传数量后,网络已恢复,此时无影响。
断网时间较长,中间触发几次上报,网络错误会导致上报失败。之后恢复网络,后续日志正常上报,此时丢失了断网期间数据。
断网从某一刻开始持续到用户主动关闭页面,期间日志均无法上报。
我们可以尝试增加“失败重传”的功能,比起网络不稳定,更多的情况是某个问题导致的稳定错误,重传不能解决这类问题。设想我们在客户端进行数据收集,我们可以很方便地记录到log文件中,于是同样的考虑,我们也可以把数据暂存到localstorage上面,有网环境下再继续上报,因此解决这个问题的方案我们可以归纳为:
上报数据,navigator.onLine判断网络状况有网正常发送无网络时记入localstorage, 延时上报更好的pv: visibilitychange
PV是日志上报中很重要的一环。
目前为止我们基本实现完上报了,现在再回归到业务层面。pv的目的是什么,以及怎样更好得达到我们的目的? 推荐先阅读这篇关于pv的文章:
为什么说你的pv统计是错的
在大多数情况下,我们的pv上报假设每次页面浏览(Page View)对应一次页面加载(Page Load),且每次页面加载完成后都会运行一些统计代码, 然而这情况对于尤其单页应用存在一些问题
用户打开页面一次,而在接下来的几天之内使用数百次,但是并没有刷新页面,这种情况应该只算一个 Page View 么如果两个用户每天访问页面次数完全相同,但是其中一个每次刷新,而另一个保持页面在后台运行,这两种使用模式的 Page View 统计结果应该有很大的不同么为了遵循更好的PV,我们可以在脚本增加下列情况的处理:
页面加载时,如果页面的 visibilityState 是可见的,发送 Page View 统计;页面加载时, 如果页面的 visibilityState 是隐藏的,就监听 visibilitychange 事件,并在 visibilityState 变为可见时发送 Page View 统计;如果 visibilityState 由隐藏变为可见,并且自上次用户交互之后已经过了“足够长”的时间,就发送新的 Page View 统计;如果 URL 发生变化(仅限于 pathname 或 search 部分发送变化, hash 部分则应该忽略,因为它是用来标记页面内跳转的) 发送新的 Page View 统计考虑到不同业务场景,我们还有有更多空间可以填补,数据闭环其实也是为了更好的业务分析服务,虽然是一个传统功能,但值得细细考究的点还是挺多的吧
作者:这个前端不太冷
链接:https://www.jianshu.com/p/222c5cc2372b
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
从电商页面埋点说起
相关内容
- python3之利用字典和列表实现城市多级菜单,,利用字典
- Python - 100天从新手到大师,,简单的说,Pytho
- Python可视化 | Seaborn包—kdeplot和distplot,,import pan
- Python中安装框架如何换源,,想安装tornado
- python 学习_collection,,collection
- python练习-8.12,,注:本代码是《pyt
- python的xlwt模块,,xlwt模块用来设置
- python Socket编程-python API 与 Linux Socket API之间的关系,
- Python迭代器,,一、可迭代的对象、迭
- python_发送请求类,,一、发送请求类imp
评论关闭