在Python中实现你自己的推荐系统,python实现推荐,人们口味各异,但通常有迹
在Python中实现你自己的推荐系统,python实现推荐,人们口味各异,但通常有迹
现今,推荐系统被用来个性化你在网上的体验,告诉你买什么,去哪里吃,甚至是你应该和谁做朋友。人们口味各异,但通常有迹可循。人们倾向于喜欢那些与他们所喜欢的东西类似的东西,并且他们倾向于与那些亲近的人有相似的口味。推荐系统试图捕捉这些模式,以助于预测你还会喜欢什么东西。电子商务、社交媒体、视频和在线新闻平台已经积极的部署了它们自己的推荐系统,以帮助它们的客户更有效的选择产品,从而实现双赢。
两种最普遍的推荐系统的类型是基于内容和协同过滤(CF)。协同过滤基于用户对产品的态度产生推荐,也就是说,它使用“人群的智慧”来推荐产品。与此相反,基于内容的推荐系统集中于物品的属性,并基于它们之间的相似性为你推荐。一般情况下,协作过滤(CF)是推荐引擎的主力。该算法具有能够自身进行特征学习的一个非常有趣的特性,这意味着它可以开始学习使用哪些特性。CF可以分为基于内存的协同过滤和基于模型的协同过滤。在本教程中,你将使用奇异值分解(SVD)实现基于模型的CF和通过计算余弦相似实现基于内存的CF。我们将使用MovieLens数据集,它是在实现和测试推荐引擎时所使用的最常见的数据集之一。它包含来自于943个用户以及精选的1682部电影的100K个电影打分。你应该添加解压缩的movielens数据文件夹你的notebook目录下。你也可以在这里下载数据集。
import numpy as np
import pandas as pd
读入u.data文件,它包含完整的数据集。你可以 file, which contains the full dataset. You can在这里阅读该数据集的简要说明。
header = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv('ml-100k/u.data', sep='\t', names=header)
先看看数据集中的前两行。接下来,让我们计算唯一用户和电影的数量。
n_users = df.user_id.unique().shape[0]
n_items = df.item_id.unique().shape[0]
print 'Number of users = ' + str(n_users) + ' | Number of movies = ' + str(n_items)
Number of users = 943 | Number of movies = 1682
你可以使用scikit-learn库将数据集分割成测试和训练。Cross_validation.train_test_split根据测试样本的比例(test_size),本例中是0.25,来将数据混洗并分割成两个数据集。
from sklearn import cross_validation as cv
train_data, test_data = cv.train_test_split(df, test_size=0.25)
基于内存的协同过滤
基于内存的协同过滤方法可以分为两个主要部分:用户-产品协同过滤和产品-产品协同过滤。一个用户-产品协同过滤将选取一个特定的用户,基于打分的相似性发现类似于该用户的用户,并推荐那些相似用户喜欢的产品。相比之下,产品-产品协同过滤会选取一个产品,发现喜欢该产品的用户,并找到这些用户或相似的用户还喜欢的其他的产品。输入一个产品,然后输出其他产品作为推荐。
- 用户-产品协同过滤: “喜欢这个东西的人也喜欢……”
- 产品-产品协同过滤: “像你一样的人也喜欢……”
在这两种情况下,从整个数据集构建一个用户-产品矩阵。由于你已经将数据拆分到测试集和训练集,那么你将需要创建两个[943 x 1682]矩阵。训练矩阵包含75%的打分,而测试矩阵包含25%的打分。
用户-产品矩阵的例子: 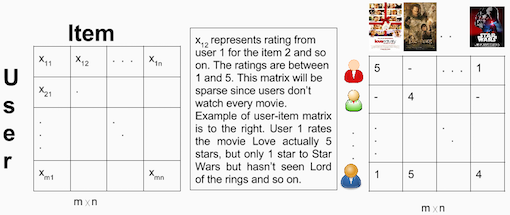
在构建了用户-产品矩阵后,计算相似性并创建一个相似性矩阵。
在产品-产品协同过滤中的产品之间的相似性值是通过观察所有对两个产品之间的打分的用户来度量的。
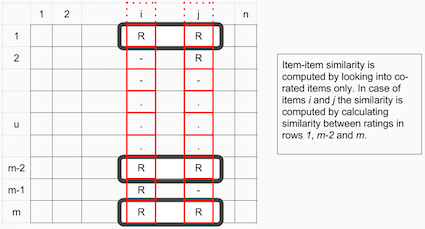
对于用户-产品协同过滤,用户之间的相似性值是通过观察所有同时被两个用户打分的产品来度量的。
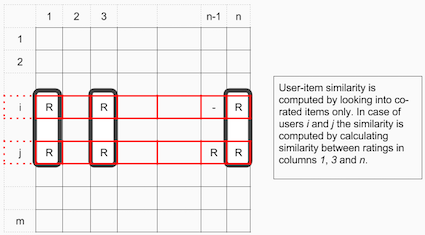
通常用于推荐系统中的距离矩阵是余弦相似性,其中,打分被看成n维空间中的向量,而相似性是基于这些向量之间的角度进行计算的。用户a和m的余弦相似性可以使用下面的公式进行计算,其中,获取用户向量的点积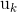 和
和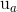 ,然后用向量的欧几里得长度的乘积来除以它。
,然后用向量的欧几里得长度的乘积来除以它。 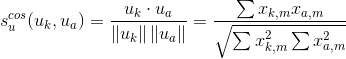
要计算产品m和b之间的相似性,使用公式:
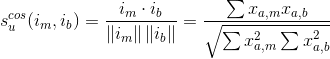
第一步是创建用户-产品矩阵。由于你既有测试数据,又有训练数据,那么你需要创建两个矩阵。
#Create two user-item matrices, one for training and another for testing
train_data_matrix = np.zeros((n_users, n_items))
for line in train_data.itertuples():
train_data_matrix[line[1]-1, line[2]-1] = line[3]
test_data_matrix = np.zeros((n_users, n_items))
for line in test_data.itertuples():
test_data_matrix[line[1]-1, line[2]-1] = line[3]
你可以使用sklearn的pairwise_distances函数来计算余弦相似性。注意,输出范围从0到1,因为打分都是正的。
from sklearn.metrics.pairwise import pairwise_distances
user_similarity = pairwise_distances(train_data_matrix, metric='cosine')
item_similarity = pairwise_distances(train_data_matrix.T, metric='cosine')
下一步是做出预测。你已经创建了相似性矩阵:user_similarity和item_similarity,因此,你可以通过为基于用户的CF应用下面的公式做出预测:
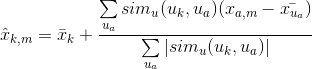
你可以将用户k和a之间的相似性看成权重,它乘以相似用户a (校正的平均评分用户)的评分。你需要规范化该值,使打分位于1到5之间,最后,对你尝试预测的用户的平均评分求和。
这里的想法是,某些用户可能会倾向于对所有的电影,总是给予高或低评分。这些用户提供的评分的相对差比绝对评分值更重要。举个例子:假设,用户k对他最喜欢的电影打4星,而对所有其他的好电影打3星。现在假设另一个用户t对他/她喜欢的电影打5星,而对他/她感到无聊的电影打3星。那么这两个用户可能品味非常相似,但对打分系统区别对待。
当为基于产品的CF进行预测时,你无须纠正用户的平均打分,因为查询用户本事就是用来做预测的。
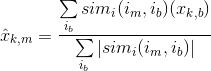
def predict(ratings, similarity, type='user'):
if type == 'user':
mean_user_rating = ratings.mean(axis=1)
#You use np.newaxis so that mean_user_rating has same format as ratings
ratings_diff = (ratings - mean_user_rating[:, np.newaxis])
pred = mean_user_rating[:, np.newaxis] + similarity.dot(ratings_diff) / np.array([np.abs(similarity).sum(axis=1)]).T
elif type == 'item':
pred = ratings.dot(similarity) / np.array([np.abs(similarity).sum(axis=1)])
return pred
item_prediction = predict(train_data_matrix, item_similarity, type='item')
user_prediction = predict(train_data_matrix, user_similarity, type='user')
评估
有许多评价指标,但其中最受欢迎的用来度量预测评分的准确性的指标是均方根误差 (RMSE)。
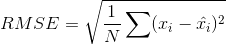
你可以使用sklearn的mean_square_error (MSE)函数,其中,RMSE仅仅是MSE的平方根。要了解更多不同的评价指标,你可以看看这篇文章。
由于你只是想要考虑测试数据集中的预测评分,因此,使用prediction[ground_truth.nonzero()]筛选出预测矩阵中的所有其他元素。
from sklearn.metrics import mean_squared_error
from math import sqrt
def rmse(prediction, ground_truth):
prediction = prediction[ground_truth.nonzero()].flatten()
ground_truth = ground_truth[ground_truth.nonzero()].flatten()
return sqrt(mean_squared_error(prediction, ground_truth))
print 'User-based CF RMSE: ' + str(rmse(user_prediction, test_data_matrix))
print 'Item-based CF RMSE: ' + str(rmse(item_prediction, test_data_matrix))
User-based CF RMSE: 3.12663244886
Item-based CF RMSE: 3.45286971684
基于内存的算法事很容易实现并产生合理的预测质量的。
基于内存的CF的缺点是,它不能扩展到真实世界的场景,并且没有解决众所周知的冷启动问题,也就是当新用户或新产品进入系统时。基于模型的CF方法是可扩展的,并且可以比基于内存的模型处理更高的稀疏度,但当没有任何评分的用户或产品进入系统时,也是苦不堪言的。
基于模型的协同过滤
基于模型的协同过滤是基于矩阵分解(MF),它已获得更大的曝光,它主要是作为潜变量分解和降维的一个无监督学习方法。矩阵分解广泛用于推荐系统,其中,它比基于内存的CF可以更好地处理与扩展性和稀疏性. MF的目标是从已知的评分中学习用户的潜在喜好和产品的潜在属性(学习描述评分特征的特征),随后通过用户和产品的潜在特征的点积预测未知的评分。
当你有一个非常稀疏的多维矩阵时,通过进行矩阵分解可以调整用户-产品矩阵为低等级的结构,然后你可以通过两个低秩矩阵(其中,每行包含该本征矢量)的乘积来代表该矩阵。你通过将低秩矩阵相乘,在原始矩阵填补缺少项,以调整这个矩阵,从而尽可能的近似原始矩阵。
让我们计算MovieLens数据集的稀疏度:
sparsity=round(1.0-len(df)/float(n_users*n_items),3)
print 'The sparsity level of MovieLens100K is ' + str(sparsity*100) + '%'
The sparsity level of MovieLens100K is 93.7%
举例说明用户和产品的学习隐藏偏好:假设MovieLens数据集中有以下信息:(user id, age, location, gender, movie id, director, actor, language, year, rating)。通过应用矩阵分解,模型学习到重要的用户特征是年龄组(10岁以下,10-18岁,18-30岁,30-90岁),位置和性别,而对于电影特性,它学习到年份,导演和演员是最重要的。现在,如果你看看你所存储的信息,其中并没有年份这样的特性,但该模型可以自己学习。重要方面是,CF模型仅使用数据(user_id, movie_id, rating)来学习潜在特征。如果只有少数可用的数据,那么基于模型的CF模式将预测不良,因为这将更难以学习潜在特征。
同时使用评分和内容特性的模型称为混合推荐系统,其中,协同过滤和基于内容的模型相结合。混合推荐系统通常比协同过滤或基于内容的模型自身表现出更高的精度:它们有能力更好的解决冷启动问题,因为如果你没有一个用户或者一个产品的评分,那么你可以使用该用户或产品的元数据进行预测。混合推荐系统将在未来的教程中介绍。
SVD
一个众所周知的矩阵分解方法是奇异值分解(SVD)。通过使用奇异值分解,协同过滤可以被近似一个矩阵X所制定。Netflix Prize比赛中的获胜队伍使用SVD矩阵分解模型来生成产品建议,更多的信息,推荐阅读文章:Netflix推荐:5星之外和Netflix Prize和SVD。
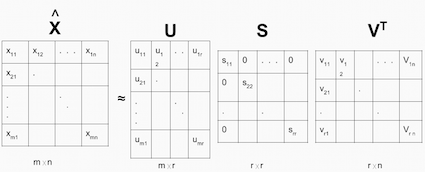
一般的方程可以表示为:
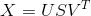
给定m x n矩阵X:
U是一个(m x r)正交矩阵S是一个对角线上为非负实数的(r x r)对角矩阵- V^T是一个
(r x n)正交矩阵
S的对角线上的元素被称为X的奇异值。
矩阵X可以被分解成U,S和V。U矩阵表示对应于隐藏特性空间中的用户的特性矩阵,而V矩阵表示对应于隐藏特性空间中的产品的特性矩阵。 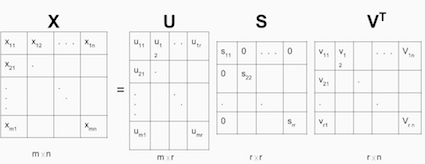
现在,你可以通过U, S和V^T的点积进行预测了。
import scipy.sparse as sp
from scipy.sparse.linalg import svds
#get SVD components from train matrix. Choose k.
u, s, vt = svds(train_data_matrix, k = 20)
s_diag_matrix=np.diag(s)
X_pred = np.dot(np.dot(u, s_diag_matrix), vt)
print 'User-based CF MSE: ' + str(rmse(X_pred, test_data_matrix))
User-based CF MSE: 2.72035726617
草草解决只有相对较少为人所知的问题是非常容易出现的过度拟合。SVD可能会非常缓慢,并且计算成本比较高。更近期的工作通过应用交替最小二乘或随机梯度下降最小化平方误差,并使用正则项以防止过 度拟合。你可以看到我们之前的一个关于随机梯度下降的教程,以获取更多详细信息。用于CF的交替最小二乘和随机梯度下降的方法将在未来的教程中介绍。
总结一下:
- 在这篇文章中,我们讲了如何实现简单的协同过滤方法,包括基于内存的CF和基于模型的CF。
- 基于内存的模型是基于产品或用户之间的相似性,其中,我们使用余弦相似性。
- 基于模型的CF是基于矩阵分解,其中,我们使用SVD来分解矩阵。
- 构建在冷启动的情况下(其中,对于新用户和新产品来说,数据不可用)表现良好的推荐系统仍然是一个挑战。标准的协同过滤方法在这样的设置下表现不佳。在接下来的教程中,你将深入研究这一问题。
相关内容
- 暂无相关文章
评论关闭