百万酒店评论数据,通过 ML 找出有趣的见解,ml见解,未经许可,禁止转载!英文
百万酒店评论数据,通过 ML 找出有趣的见解,ml见解,未经许可,禁止转载!英文
本文由 编橙之家 - Leo 翻译,艾凌风 校稿。未经许可,禁止转载!英文出处:Bruno Stecanella。欢迎加入翻译组。
文章详细分析了关于酒店住宿数据的信息,及其在各种不同方面的信息。包括了具体的详细代码和数据展示。
酒店数据机器学习分析
在之前的文章中,我们学习了如何训练一个分类器,它能检测涉及不同方面的酒店评论。有了这个分类器,我们就能自动地识别一段特定的评论是否在谈论酒店的清洁度、舒适度和配套设施、食物、 Internet 、位置、员工以及性价比。
我们也学习了怎样将这个分类器与情绪分类器整合到一起,从而得到一些有趣的信息,并回答类似“为什么顾客喜欢一个酒店所处的位置,但却抱怨其清洁程度”这样的问题。
在这篇文章里,我们将涵盖如何使用这些机器学习模型去分析从 TripAdvisor 中得到的数据,然后比较人们对于不同城市的酒店的感受,去理解一些这样的事情:
- 在曼谷住过的人们会比他们在其他城市,譬如巴黎,更抱怨酒店的清洁度吗?
- 哪座城市的酒店拥有最糟糕的配套设施?
- 酒店的星级是否会影响客户对它的评价?
- 人们对不同类型的酒店是不是有不同的评价标准?
这些都是我们打算在这篇教程回答的问题,也将引发一些有意思的思考。相关的源代码已经上传到 托管仓库 中。
爬取酒店评论
在之前的文章中我们已经开发过针对 TripAdvisor 的爬虫,现在我们创建了一个新版本,它可以从评论中收集更多的信息:
- 酒店名称
- 酒店所处的城市
- 酒店的星级(由评价者评定)
创建管道去组合这些模型
使用新的爬虫从 TripAdvisor 抓取到超过 1 百万的评论数据后,我们将内容拆分成意见单元,并用类似上次我们做过的方式对它们进行分类。这一次最大的不同是,我们创建了管道来组合这两种分类器。管道是一种非常强大并且灵活的工具,它允许你将 MonkeyLearn 中不同的模块组合起来,正因为有了它,我们才能在单次请求中同时根据酒店的不同特征和表现出的情绪对评论分类。
下面就是如何使用管道来对意见单元分类的:
Python
from monkeylearn import MonkeyLearn
ml = MonkeyLearn("<your api key here>")
data = {
"texts": [{"text": "The room was very clean"}, {"text": "very rude staff"}]
}
res = ml.pipelines.run('pi_YKStimMw', data, sandbox=False)
简单吧?那好,res.result 是 JSON 数据,看起来像这样:
JavaScript
{
'tags': [{
'sentiment': [{
'category_id': 102881,
'label': 'Good',
'probability': 1.0
}],
'topic': [
[{
'category_id': 1495678,
'label': 'Cleanliness',
'probability': 1.0
}]
]
}, {
'sentiment': [{
'category_id': 102882,
'label': 'Bad',
'probability': 1.0
}],
'topic': [
[{
'category_id': 1495676,
'label': 'Staff',
'probability': 1.0
}]
]
}]
}
每条评论都有一个项目发送到管道中,相应地拥有一种情绪和一个主题列表(不同的酒店特征)。
当保存这些结果到 CSV 文件时,我们还增加了一个指向它父评论的链接,附带上根据评论文本哈希值生成的密钥。因此,我们现在有了两个文件:一个是评论文件,包含我们抓取的每条评论的元数据(城市,酒店,位置,星级,等等);另一个是分类好的意见单元,包括每个单元的情绪和话题,对应每种情绪的概率值,以及指向父评论的链接。
Elasticsearch 索引和 Kibana 可视化
但我们不会止步于此。接下来我们将使用 Elasticsearch 对结果进行索引,并将其导入到 Kibana 来产生精美的可视化图形。
这是相当简单的。首先,我们安装好 Elasticsearch ,将其运行在单机模式下。为了找到最适合这些数据的模型,我们经过一些试验和错误之后,选择了 sense 来实现目标。有个好用的 Chrome 插件可以让你通过优雅的接口与 Elastic 的 API 交互,而不是使用 cURL 。我们创建了包含两个类型的索引:评论和意见单元。每个类型的字段都是这个 CSV 文件的字段, _parent 属性值就是我们向每个意见单元中加入的指向父评论的链接。
使用 SDK 去索引意见单元非常容易。你仅仅需要创建包括一项所有字段的 Python 字典类型,然后通过 SDK 将它发送到 elasticsearch 即可。批量处理要比单次发送一项更高效:
Python
es = Elasticsearch(['http://localhost:9200'])
actions = []
parent_key = 'bd1ed398a8529d5ad010d927d5af7240'
opinion_unit = "The room was very clean"
sentiment = "Good"
topic = "Cleanliness"
item = [parent_key, opinion_unit, sentiment, topic]
action = {
"_index": "index_hotels",
"_type": "opinion_unit",
"_id": cont_id,
"_parent": parent_key,
"_source": item
}
actions.append(action)
helpers.bulk(es, actions)
然后我们安装好 Kibana ,配置它指向到 Elasticsearch 本地实例。为了创建下面的图形,我们使用基于 JSON 格式的查询语句,而不是 Lucene ,因为要用到 has_parent 和 has_child 子句。
以下是能从纽约的评论中选取意见单元的查询语句。它使用一个包含 has_parent 的过滤子句,这意味着它只匹配那些父元素(评论)满足要求(来自纽约)的元素(意见单元)。它还要求利用上述的情绪概率来设定阈值,对意见单元的进行分类,这将提高查询结果的质量:
JavaScript
{
"query": {
"filtered": {
"query": {
"match_all": {
"range": {
"sent_probability": {
"gt": "0.501"
}
}
}
},
"filter": {
"has_parent": {
"type": "review",
"query": {
"match": {
"city": "New York City"
}
}
}
}
}
}
}
绝大部分用于创建图表的查询都与这个类似,它们可以在 Github 上获取到。
从评论中得到的领悟
绝大多数评论是正面的
从总体上看,绝大多数评论多半都倾向于积极。在分析的所有意见单元中, 82 % 拥有积极的情绪。这意味着,平均有 82 % 写在酒店评论中的内容是积极的。
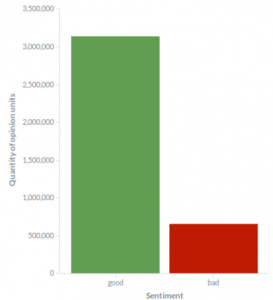
全部400万意见单元表现的情绪
伦敦的酒店评价最糟糕
然而,一旦你以城市为单位对评论表现的情绪分割,事情开始变得有趣了。对伦敦酒店的评论要比其他城市的更加严厉。我们对这个结果感到惊讶,因为我们觉得伦敦会表现出与纽约或巴黎相同的水平。因为每年有数百万的游客前往这座城市,它的评价与同等规模的城市不同会造成显著的差异:
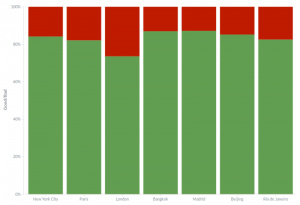
不同城市的酒店的评论表现的情绪
这个模型没有给我们任何解释这种行为的原因,只有事实。这会是恶名昭著的英式客户服务的症状吗?还是人们对伦敦的酒店比其他城市的更苛刻呢?(请在下面的评论中分享你的意见)
伦敦的酒店评论比纽约的更差,总的来说提供的食物最糟糕
另一个有趣的信息来源于在不同城市之间比较某一个特定酒店特征的评论所表现出的情绪。
酒店的某些方面保持着与游客对城市整体情绪大致相同的水平:伦敦的酒店舒适度和配套设施要差于纽约的,不一而足。
有趣的是,并不是酒店的所有方面都遵循这个模式。例如,在所有城市中,对于位置的评价都是非常正面的,说明当评论者提到酒店的位置时,通常是因为他们喜欢这里,因此很少去抱怨。食物也是类似的情况,只有伦敦再一次明显地落后于其他城市。这可能是英式烹饪得到了很坏的名声。
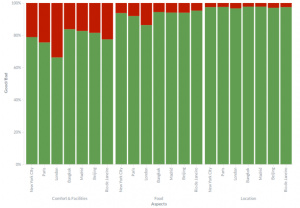
不同城市针对酒店不同方面的评价表现的情绪
对于不同星级酒店的评价情绪
我们最后做了比较,去了解人们如何看待不同的分类(星级)酒店的各个方面。因为评论的正面性随着星级的增加而增加,看起来无论游客停留在什么酒店,他们都秉持相同的标准。
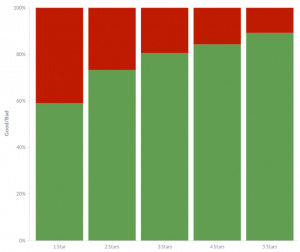
不同类型酒店的评价表现的情绪
网络问题始终存在
非常有趣的是,在任何星级的酒店中,客户对网络的好评率都不超过 70 % ,这说明 3 星级酒店的网络访问情况和 5 星级酒店的一样糟糕。某些人会认为高档的酒店就能提供更好的网络服务,但当你真的住在5星级酒店时就会发现并非如此。
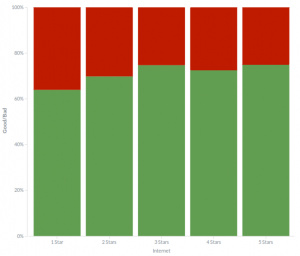
针对不同星级酒店的网络评价表现的情绪
3 星级酒店拥有最高的性价比
性价比是酒店评论中表现出差异性的另一个方面,正面情绪在 3 星级酒店达到了顶峰,接下来开始下降。这意味着, 3 星级甚至 2 星级的酒店总的来说拥有更高的性价比,即使它们相比高档次的酒店存在着更多方面的负面评价。
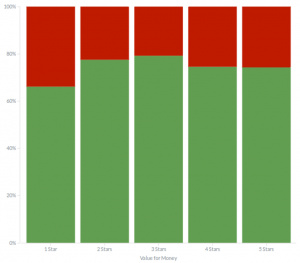
不同星级酒店的性价比评价
使用关键词提取进行上下文分析
数字看起来是没问题的,但实际的内容呢?在针对酒店清洁度的评论中,每个城市被赞扬的是什么?顾客对每个酒店的食品都有哪些常见的抱怨?为了找出答案,我们使用了关键字提取模块。这是一个开放的模块,能对给定的文本,提取其关键字并依据相关性排序。
为了从每一段中获得有代表性的关键词,我们把相同城市、酒店特征和情绪的数百个意见单元组合起来,放入一个文本中,从中提取出关键词。下面介绍了如何运行这个关键字提取器:
Python
ml = MonkeyLearn("<your api key here>")
text = ["The carpets are a disgrace in the dining room and need replaced immediately. The room was frankly grim....old, saggy beds (all 3 of them), scuffed walls and decor, the hotel is SO old, smells old, and TINY!"]
module_id = 'ex_y7BPYzNG'
res = ml.extractors.extract(module_id, text)
返回的结果是一个 JSON ,包含了提取出的关键词和关于它们的信息,譬如相关性和出现次数。
例如,以下是 MonkeyLearn 返回的针对纽约酒店的负面评论中,在清洁度方面与不好的情绪关联度最高的十个关键词:
Python
for d in res.result[0]:
print d["keyword"], d["relevance"]
room 0.999
bathroom 0.790
carpet 0.407
towels 0.311
bed bugs 0.246
bed 0.232
hotel 0.196
shower 0.155
shared bathroom 0.150
walls 0.138
针对每个部分的关键字提取完成后,我们比较了从不同的城市获得的关键字:哪些是独特的,哪些是常见的。
曼谷的酒店存在蟑螂
这种分析给我们提供了一些关于每个城市的酒店之间的差异性和相似性的有趣见解。
举例来说,通常抱怨每座城市酒店的卫生都是像毛毯、床、头发、床虱、污渍这些东西。然而,只有曼谷的酒店评论中出现了蟑螂,这说明在曼谷的酒店里蟑螂的情况可能比其他地方糟糕多了。
共用卫生间只出现在纽约,这可能意味着在纽约共用卫生间是比较常见的,而且卫生状况堪忧!
有关酒店位置的观点在城市之间变化很大。每个城市都有不同的地标关键字:在里约热内卢,评论会提及科帕卡瓦纳、伊帕内玛;在北京,会提及紫禁城和天安门广场;在马德里会提及太阳门广场,诸如此类。这些都是每座城市中最能吸引游客的地方,所以评论者考虑酒店位置时把它们看得很重要。还有一些从城市特点的角度被提到的其他元素,例如伦敦地铁站和巴黎地铁,不再是地标。
羊角面包真让人失望!
在这个数据集背后隐藏了许多的信息,但我们还想再提一个。那就是在不同城市里对于酒店所提供食物的看法。早餐当然是一个常见的关键词,咖啡和茶同样也是。然而,当我们单独考虑一座城市的关键字时,事情就变得更加有趣了。
例如,关键字“羊角面包”只出现在那些来自巴黎的评论。此外,它主要出现在带有负面情绪的语境中,这是令人感到惊讶的。为什么一道法国主食会得到如此负面的评价?观察这些评论的上下文,答案就一目了然:羊角面包出现在顾客提及到基本早餐的语境中。所以如果你要去巴黎,普通的早餐肯定会包含羊角面包(除此之外就没别的了)。
结束语
在这篇教程中,我们学习了怎样抓取数百万的评论,使用 MonkeyLearn 内置的预先训练好的分类器对数据进行分析,并将结果用 Elasticsearch 索引,最后导入到 Kibana 实现可视化。
当你想分析大规模的数据时,使用机器学习就显得很划算并且有意义了。
我们发现了一些相当有趣的信息;一部分在意料之中(比如一直出问题的网络),一部分却出乎我们的意料(伦敦的酒店看起来像是最糟糕的)。
如果你有机会查看源代码并完成分析,你将会发现用机器学习操纵数据是件很有乐趣的事情。如果你这样做了,请在评论里分享你的观点和结果,我们很乐意去倾听你的见解。
打赏支持我翻译更多好文章,谢谢!
打赏译者
打赏支持我翻译更多好文章,谢谢!

评论关闭