NBSVM的Python实现,NBSVMPython实现,NBSVM朴素贝叶斯
NBSVM的Python实现,NBSVMPython实现,NBSVM朴素贝叶斯
NBSVM
朴素贝叶斯(Naive Bayers))和支持向量机(SVM)是文本分类常用的基础模型。在不同的数据集、不同的特征和不同的参数下,两者的效果有所差异。一般来说NB在短文本上的表现要优于SVM,而SVM在长文本上的表现更佳。
NBSVM来自论文<Baselines and Bigrams Simple, Good Sentiment and Topic Classification>,是作者提出的一种新型的分类方法,它将NB和SVM结合起来,原理可以概括为一句话:
"Trust NB unless SVM is very confident"
作者在不同的数据集上进行了实验,都取得了比单独的NB和SVM更好的效果,具体结果和原理方法可参见原论文。
作者也提供了matlab代码,本文将用python对nbsvm进行简单demo实现。
问题描述
实现一个小型的中文新闻文本分类问题。训练集数据由11类新闻组成,文本已经做好了分词;每类新闻有1600条,对应的标签由1到11。测试集由11*160条数据组成。 实验数据和对比的结果来自知乎专栏,详细地址见参考。
算法步骤
向量化,TF-IDF特征提取count_v0= CountVectorizer(); counts_all = count_v0.fit_transform(train_x +test_x);count_v1= CountVectorizer(vocabulary=count_v0.vocabulary_); counts_train = count_v1.fit_transform(train_x); print ("the shape of train is "+repr(counts_train.shape) )count_v2 = CountVectorizer(vocabulary=count_v0.vocabulary_); counts_test = count_v2.fit_transform(test_x); print ("the shape of test is "+repr(counts_test.shape) ) tfidftransformer = TfidfTransformer(); train_x = tfidftransformer.fit(counts_train).transform(counts_train);test_x = tfidftransformer.fit(counts_test).transform(counts_test); 计算log-count-ratio为了简化问题,我们将多分类(N类)问题转化为若干个二分类问题,因此需要将标签转化为One-Hot编码形式,相应的y_i取值为1和0。
def pr(x, y_i, y): p = x[y==y_i].sum(0) # axis = 0 return (p+1) / ((y==y_i).sum()+1) #正则化 r = sparse.csr_matrix(np.log(pr(x,1,y) / pr(x,0,y)))用 x·r (elementwise-product)代替线性分类器中的原来的训练数据x,作为NBSVM的训练数据。
x_nb = x.multiply(r)使用新的训练数据和训练标签,进行分类器训练,这里用的LR分类器。
clf = LogisticRegression(C=1, dual=False, n_jobs=1).fit(x_nb, y)预测测试集,也将测试集的数据进行同样的x_test·r 处理。
clf.predict(x_test.multiply(r))
实验结果
在验证集的准确率达到0.8565。下表是其他方法在该数据集上分类的实验效果。
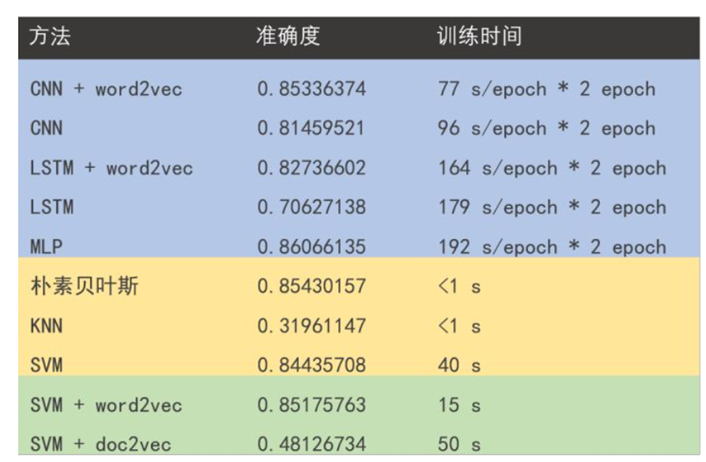
可以看出,nbsvm在不仅提高了朴素贝叶斯和SVM方法的单独作用,而且与深度学习的方法相比用时更少,效果丝毫不逊色。
感想
文本分类模型中,由于数据集和特征的差异,最优的基础分类模型往往没有确定答案。针对这个问题,NBSVM通过训练一个权重系数(可以看作是对模型的一种正则化)将两种最常见的基础分类模型很好的结合起来,形成一种通用性强、效果更佳的基础模型。
笔者后续对nbsvm应用在更大规模的数据集上(10W+),发现nbsvm的性能越能拉开单独的nb和svm的性能,并且也好于大多数浅层的深度学习模型。因此,nbsvm可以作为文本分类的一个很好的baseline模型。
NBSVM 完整代码
class NbSvmClassifier(BaseEstimator,ClassifierMixin): def __init__(self, C=1.0, dual=False, n_jobs=1): self.C = C self.dual = dual self.n_jobs = n_jobs def predict(self, x): # Verify that model has been fit check_is_fitted(self, [‘_r‘, ‘_clf‘]) return self._clf.predict(x.multiply(self._r)) def predict_proba(self, x): # Verify that model has been fit check_is_fitted(self, [‘_r‘, ‘_clf‘]) return self._clf.predict_proba(x.multiply(self._r)) def fit(self, x, y): # Check that X and y have correct shape x, y = check_X_y(x, y, accept_sparse=True) def pr(x, y_i, y): p = x[y==y_i].sum() print (p) print ((y==y_i).sum()) return (p+1) / ((y==y_i).sum()+1) self._r = sparse.csr_matrix(np.log(pr(x,1,y) / pr(x,0,y))) #pr(x,1,y) number of positve samples pr(x,0,y) number of negatve samples x_nb = x.multiply(self._r) self._clf = LogisticRegression(C=self.C, dual=self.dual, n_jobs=self.n_jobs).fit(x_nb, y) return self
完整代码地址:https://github.com/sanshibayuan/NBSVM
参考:
https://github.com/sidaw/nbsvm
https://nlp.stanford.edu/~sidaw/home/projects:nbsvm
https://zhuanlan.zhihu.com/p/26729228
NBSVM的Python实现
相关内容
- python+selenium 定位隐藏元素,pythonselenium,定位隐藏要素的
- Python条件语句,python语句,Python条件语句
- python库使用整理,python库整理,1. 环境搭建l P
- Python_基础_(面向对象三大特性),python三大,一,继承#
- CentOS7修复python拯救yum,centos7pythonyum, 本人正在吹着空调
- python第三十五天-----作业完成--学校选课系统,python第三
- Python爬虫下载美女图片(不同网站不同方法),,声明:
- python与redis,pythonredis,1.什么是redis
- Python中where()函数的用法,pythonwhere,where()的用法
- Python里面有许多成熟方便的库,,python有许多方便,Py
评论关闭