Scrapy + Flask + Mongodb + Swift 开发爬虫全攻略(1),scrapyflask,第一个叫做Scrapy的
Scrapy + Flask + Mongodb + Swift 开发爬虫全攻略(1),scrapyflask,第一个叫做Scrapy的
先一一介绍一下上面4个东西。第一个叫做Scrapy的东西是用python写的爬虫框架。
Flask是python写的一个非常有名的web开发框架,python界有两个名气最大的web开发框架,Flask是其中之一,另一个叫做Django,为什么不用Django的原因就是Django太庞大了,我们开发服务端并不需要render html之类的view层,只需要提供Restful接口,所以使用Django开发不是个明智的选择,而且Django内置了很多多余的功能,而Flask比较精简,很多额外的功能都可以通过安装Flask的扩展来实现。
Mongodb是一个非关系型数据库,它存储数据的方式不同于mysql等关系型数据库,是以key-value形式存取数据的,总的来说数据格式有点像json。和mysql各有优劣。我们这里将会使用mongodb来做我们的数据库。
Swift不多说了,iOS开发都懂得。
那么,这个系列的教程到底是想干什么呢?简单来说,就是实现一个人完成获得资源+编写服务端+iOS客户端+服务端部署上线+客户端上AppStore。这是个漫长的过程,我也在学习过程中,可能过程中唯一轻松的就是iOS客户端编写的部分,所以我把这个部分放在最后,先做最难得。再做简单的。
我之前是从来没有写过服务端的,只有大四的时候写过一个月左右的JSP,那都是很多年前的老黄历了,当时用的好像还是serverlet之类的东西。
所以用python编写服务端我也是头一遭。肯定漏洞百出,代码极其ugly,不过他山之石,可以攻玉。每个人都可以在我写这篇的过程中提出意见和建议。我们共同进步。
废话不多说。我们开始第一步,写一个爬虫获取我们需要的资源。
其实这里的内容大部分学自我前几天转发的那篇bloghttp://python.jobbole.com/81320/
看过我blog的同学应该有印象,我年前的时候有用BeautifulSoup和urllib这两个python框架写过一个爬虫,用来爬www.dbmeizi.com这个网站的美女图片。那么今天,我会用scrapy编写一个功能更完整的爬虫。他有如下几个功能。
1.爬取dbmeizi.com上每个图片的url和title。
2.把图片url和title和一些自定义字段放在mongodb里。
首先确保你的mac安装了xcode的commandline工具和python界的cocoapods,叫做pip,还有mongodb(可以去官网下载)。
然后安装scrapy这个python库,很简单。在Terminal里运行sudo pip install scrapy,输入密码之后点击回车。搞定。
我们的爬虫爬完数据之后需要把数据存入mongodb,所以需要一个用来连接mongodb的第三方库,这个库叫做"pymongo",我们也可以用pip来安装。
sudo pip install pymongo,就可以安装了。
接下来,用scrapy startproject(这两个单词合起来是一个命令)来生成一个爬虫。
输入scrapy startprojct dbmeizi
然后scrapy帮我们生成了这么一个模板。
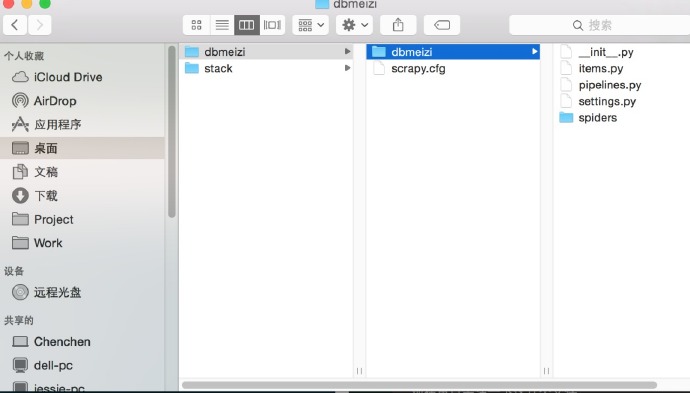
现在重点关注一下这几个文件。
1.items.py,这里你可以吧items.py看作是mvc中的model,在items里我们定义了自己需要的模型。
2.piplines.py pipline俗称管道,这个文件主要用来把我们获取的item类型存入mongodb
3.spiders文件夹。 这里用来存放我们的爬虫文件。
4.settings.py 这里需要设置一些常量,例如mongodb的数据库名,数据库地址和数据库端口号等等。
第一步:定义Model层
我们可以先设想一下,dbmeizi.com这个网站,每一个美女图片包括哪些内容?
我们先看一张图。

这张图显示了dbmeizi.com这个网站里每张图片包含的信息。所以我们可以规定model有以下内容。
1.image的URL
2.image的title
3.可以设置一个star以后可以用来排序,让用户打分,看看哪个美女最受欢迎
4.还有一个id,防止后面插入数据库的时候插入重复数据
ok,所以打开items.py我们修改后的代码是这样的。
Python
from scrapy.item import Item, Field
class MeiziItem(Item):
# define the fields for your item here like:
# name = scrapy.Field()
datasrc = Field()
title = Field()
dataid = Field()
startcount = Field()
我们定义了一个class叫做MeiziItem,继承自scrapy的类Item,然后为我们的类定义了4个属性,datasrc用来保存等下拉去的image-url,title用来保存图片的title,dataid用来记录图片id防止重复图片,starcount是喜欢次数,以后我们开发iOS端的时候可以设计一个喜欢的功能。每次用户喜欢那么startcount都+1.
第二步:编写爬虫
打开spiders文件夹,新建一个dbmeizi_scrapy.py文件。
在文件里写如下内容.
from scrapy import Spider
from scrapy.selector import Selector
from dbmeizi.items import MeiziItem
class dbmeiziSpider(Spider):
name = "dbmeiziSpider"
allowed_domin =["dbmeizi.com"]
start_urls = [
"http://www.dbmeizi.com",
]
def parse(self, response):
liResults = Selector(response).xpath('//li[@class="span3"]')
for li in liResults:
for img in li.xpath('.//img'):
item = MeiziItem()
item['title'] = img.xpath('@data-title').extract()
item['dataid'] = img.xpath('@data-id').extract()
item['datasrc'] = img.xpath('@data-src').extract()
item['startcount'] = 0
yield item
可能很多人看到这就晕菜了。我尽量尝试讲的清楚明白。
首先我们定义了一个类名为dbmeiziSpider的类,继承自Spider类,然后这个类有3个基础的属性,name表示这个爬虫的名字,等一下我们在命令行状态启动爬虫的时候,爬虫的名字就是name规定的。
allowed_domin意思就是指在dbmeizi.com这个域名爬东西。
start_urls是一个数组,里面用来保存需要爬的页面,目前我们只需要爬首页。所以只有一个地址。
然后def parse就是定义了一个parse方法(肯定是override的,我觉得父类里肯定有一个同名方法),然后在这里进行解析工作,这个方法有一个response参数,你可以把response想象成,scrapy这个框架在把start_urls里的页面下载了,然后response里全部都是html代码和css代码。
然后,liResults = Selector(response).xpath('//li[@class="span3"]')?这句话什么意思呢?
这句话的意思就是从html里的最开始一直到最后,搜索所有class="span3"的li标签。
我们获得了li这个标签后,再通过for img in li.xpath('.//img'):这个循环取出所有img标签,最后一个for循环里新建我们之前创建的MeiziItem,然后赋值。
如果实在看不懂,那么你需要看两个东西一个是xpath,一个是我之前写的一片《iOS程序员写爬虫》那篇blog。
Ok,我们的爬虫写好了。
第三步:将我们的MeiziItem存入数据库中
打开settings.py,我们修改成如下样子。
PythonBOT_NAME = 'dbmeizi' SPIDER_MODULES = ['dbmeizi.spiders'] NEWSPIDER_MODULE = 'dbmeizi.spiders' ITEM_PIPELINES = ['dbmeizi.pipelines.MongoDBPipeline',] MONGODB_SERVER = "localhost" MONGODB_PORT = 27017 MONGODB_DB = "dbmeizi" MONGODB_COLLECTION = "meizi" # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'stack (+http://www.yourdomain.com)'
请注意ITEM_PIPELINES那个常数,这个常数是用来规定我们获取爬虫爬下来的数据并将之转为model类型之后应该做什么事。很简单,这个常数告诉我们转为model类型之后区pipelines.py里找MongoDBPipeline这个class。这个class会替我们完成接下来的工作。
下面几个MONGODB打头的常数用来规定MONGODB的一些基本信息,比如server是哪个啊,端口是哪个之类的。
强烈建议自己去简单的学习一下mongodb基础知识。起码会简单的增删改查,在mongodb的shell里多练练,要不然完全看不懂。
在settings.py里修改之后,我们打开pipelines.py。修改如下。
Python
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Meizi added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
我们定义了一个类,名字叫做MongoDBPipeline,注意,这个名字是与我们在settings里的ITEM_PIPELINES这个常数里面规定的时一致的。注意别写错了。
init就是python中的构造方法,这个方法里我们主要是建立于mongodb的链接,所以用上了pymongo这个框架。然后将一个collection作为类的一个属性,在mongodb中,一个collection你可以想象成mysql中的一个table。
在process_item这个方法中,我们主要是将item存入数据库。注意self.collection.insert(dict(item))这句话,就是将我们的MeiziItem存入数据库。
ok,大功告成,我们现在运行一下。
1.启动mongodb

2.运行爬虫
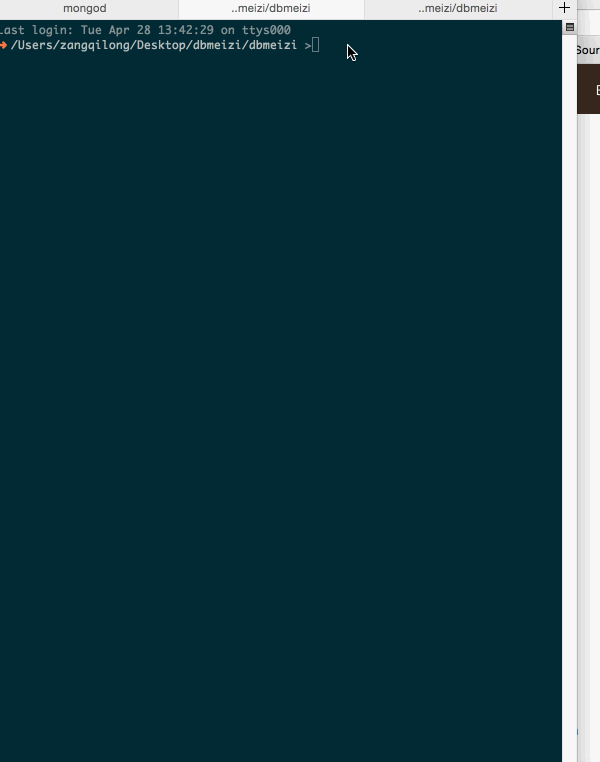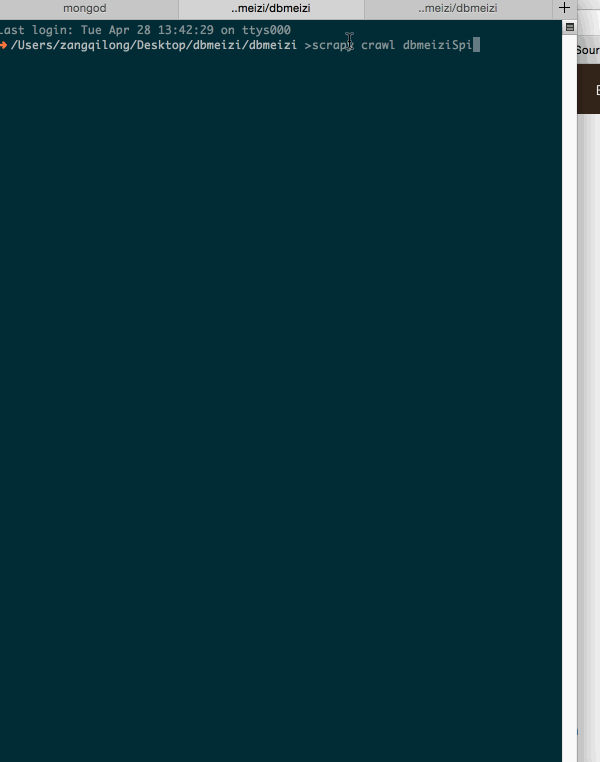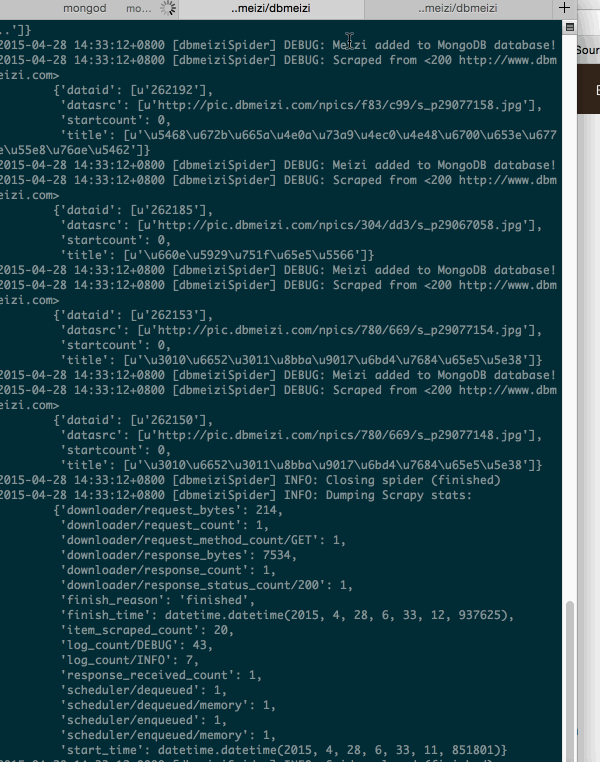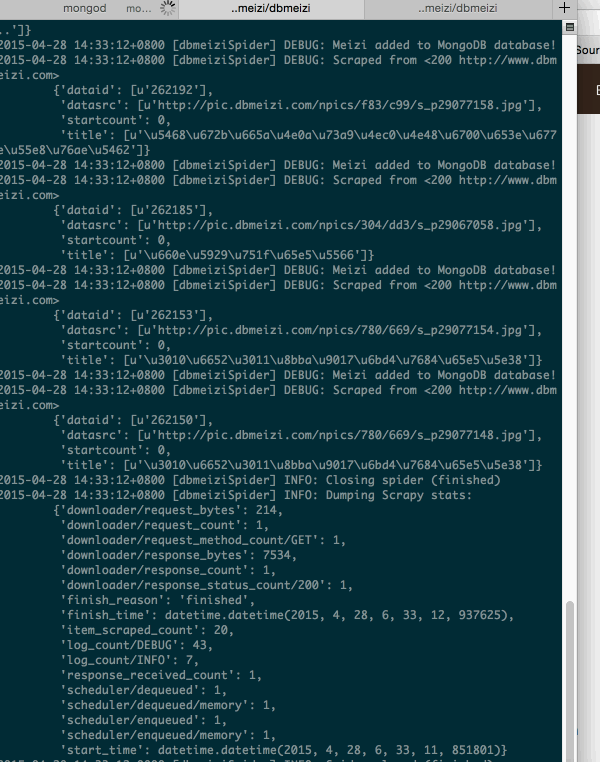
3.检查我们的数据库是否有数据
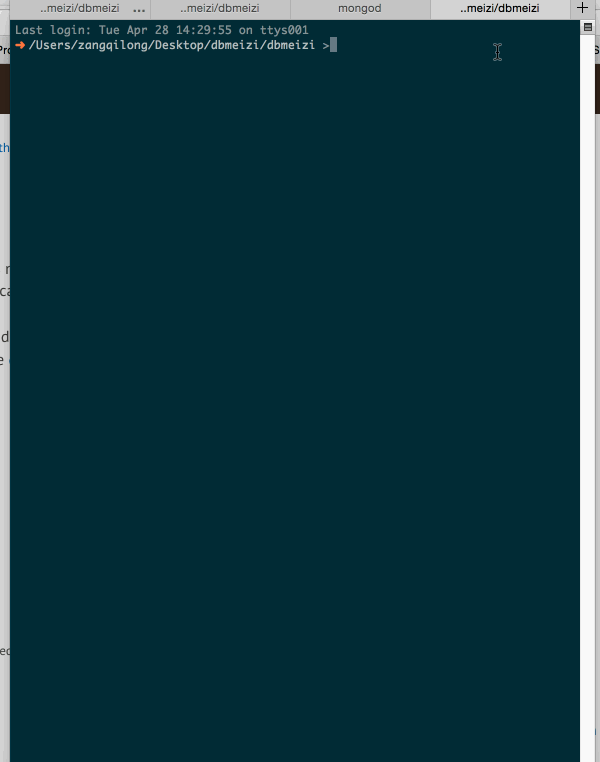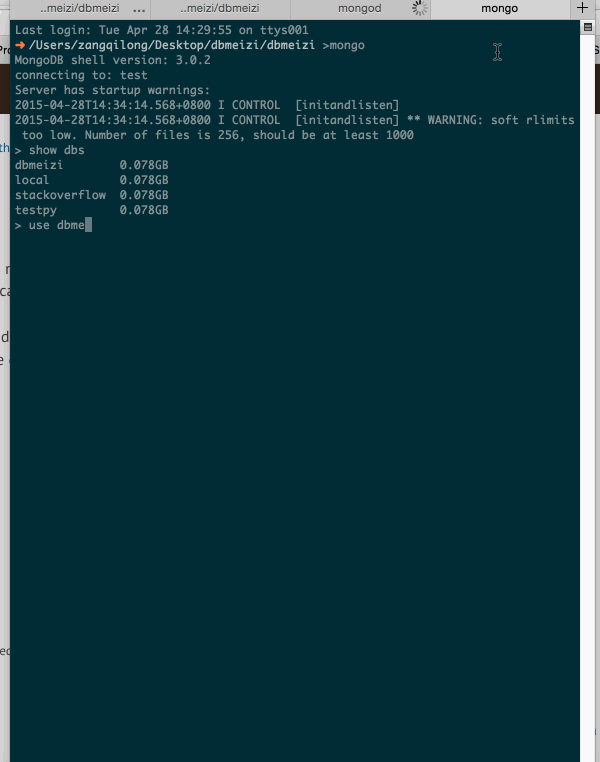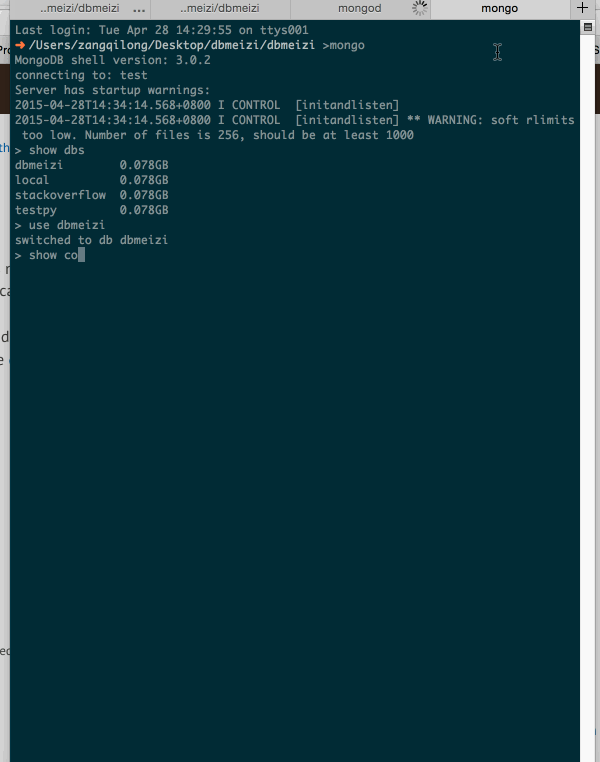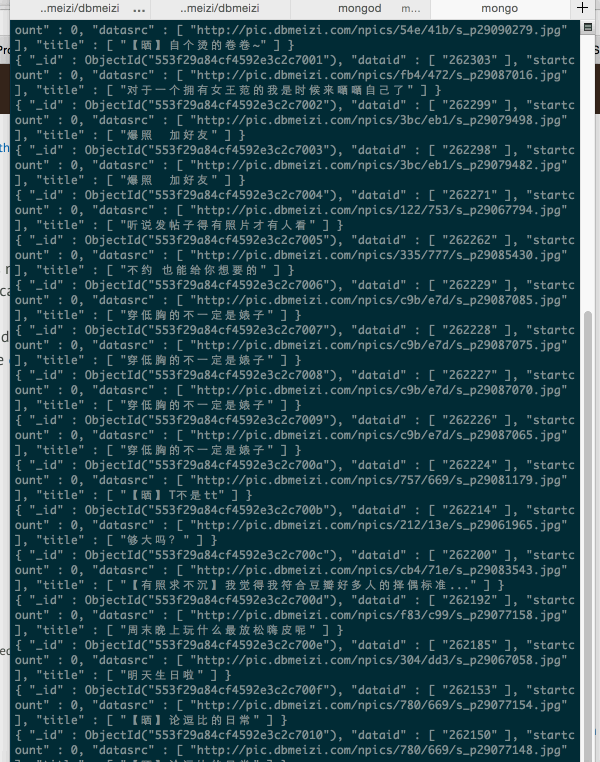
大功告成。
如果你编写的爬虫老是运行不了,首先检查是否用pip安装了需要的框架,或者哪里写错了。
最后放上github地址:
https://github.com/zangqilong198812/DbMeiziScrapy
相关内容
- Scrapy+Flask+Mongodb+Swift开发全攻略(2),scrapyflask,第一件
- Scrapy+Flask+Mongodb+Swift开发全攻略(3),scrapyflask, 那么我
- 这不是魔法:Flask和@app.route(2),flask@app.route,未经许
- 用Flask实现视频数据流传输,flask视频数据流,未经许可
- flask 源码解析:响应,flask源码解析响应, The return
- flask 源码解析:上下文,flask源码,只有像Add这种简单的
- flask 源码解析:请求,flask源码解析请求, 可以看到,虽
- flask 源码解析:session,flasksession,session 可以看做
- 如何理解Nginx、uWSGI和Flask之间的关系?,nginxflask,不同
- Flask中的请求上下文和应用上下文,flask上下文,整个请
评论关闭